


在当今大数据时代,处理庞大的数据集已成为许多组织面临的挑战,Hadoop框架中的MapReduce技术提供了一种解决方案,它允许将大数据集分成多个小数据块,通过在多个节点上并行处理来加速数据的处理速度,本文旨在深入探讨MapReduce中的任务调度机制,分析其工作原理及调度算法,并讨论其在现代数据处理中的应用和挑战。
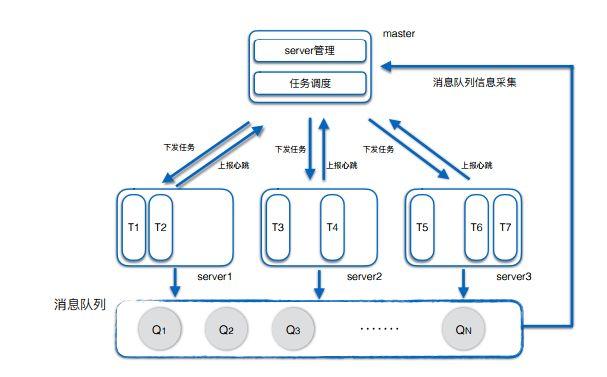

MapReduce任务调度的基本概念需要被准确理解,在Hadoop框架中,MapReduce作业是由JobTracker进行管理和调度的,当一个MapReduce作业被提交到系统时,它会首先被分解成多个小任务,包括映射(Map)任务和归约(Reduce)任务,JobTracker根据TaskTracker发送的心跳信息来评估各节点的资源使用情况和健康状况,进而决定将哪些任务分配给哪个TaskTracker执行[^1]。
了解MapReduce中的任务调度模型是至关重要的,任务调度模型涉及到如何根据当前资源状况合理地分配和调度任务,在MapReduce环境中,这通常意味着要在处理能力不同的节点间平衡负载,同时考虑到数据的本地性(data locality),即尽可能将任务调度到数据存储的节点上执行,以减少网络传输造成的延迟[^2]。
深入到任务调度算法,这是MapReduce任务调度中的核心部分,任务调度算法负责根据任务特性和资源情况,合理地将任务分配给可用资源,在MapReduce中,常见的调度算法包括FIFO(先进先出)、公平调度器(Fair Scheduler)和容量调度器(Capacity Scheduler),这些算法有不同的优化目标,如FIFO简单直接但可能不利于小作业的快速处理;公平调度器试图为所有作业提供平等的资源份额,而容量调度器则允许用户为不同队列设定资源容量,以适应多用户共享集群的场景[^5]。
MapReduce任务调度的执行原理也不可忽视,当TaskTracker准备好接受新任务时,它会向JobTracker发送心跳信息,JobTracker接收到心跳后,会根据任务优先级、输入数据的位置和TaskTracker的能力来决定是否分配一个新任务,此过程中,JobTracker还需要处理任务失败的情况,重新调度失败的任务以确保作业能顺利完成[^1]。
在实际应用中,MapReduce任务调度面临多种挑战,如如何处理节点故障、如何优化调度策略以适应不同类型的作业需求等,处理大规模实时数据流时,调度器可能需要动态调整资源分配,以保证数据处理的低延迟和高吞吐量,随着计算需求的多样化,传统的调度算法可能需要进一步优化或引入新的调度策略以提高效率和适应性。
MapReduce任务调度的优化策略也是提升性能的关键,这包括采用更先进的调度算法、改进数据本地性策略、以及优化任务和资源的匹配过程,通过这些措施,可以显著提高MapReduce作业的执行效率和资源利用率。
MapReduce中的任务调度是一个复杂但极其重要的环节,它直接影响到作业的执行效率和资源利用率,通过理解其基本原理、调度模型和算法,以及面临的挑战和优化策略,可以更好地管理和优化大数据处理流程,实现高效且稳定的数据分析环境。
相关问答FAQs
Q1: MapReduce任务调度中的数据本地性是什么?
A1: 数据本地性是指在进行任务调度时,优先选择将任务分配给存储有该任务所需数据的节点上执行,目的是减少网络传输造成的延迟,提高数据处理速度。
Q2: 如何选择合适的MapReduce任务调度算法?
A2: 选择合适的MapReduce任务调度算法应考虑作业的特性、集群的使用模式以及用户的需求,对于小作业密集的环境,可以考虑使用公平调度器来确保每个作业都能获得合理的资源分配;而在多用户共享的大集群环境下,容量调度器可能是更合适的选择,因为它允许为不同队列设定资源容量,满足不同用户的需求。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/891731.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复