


配置MapReduce Job基线
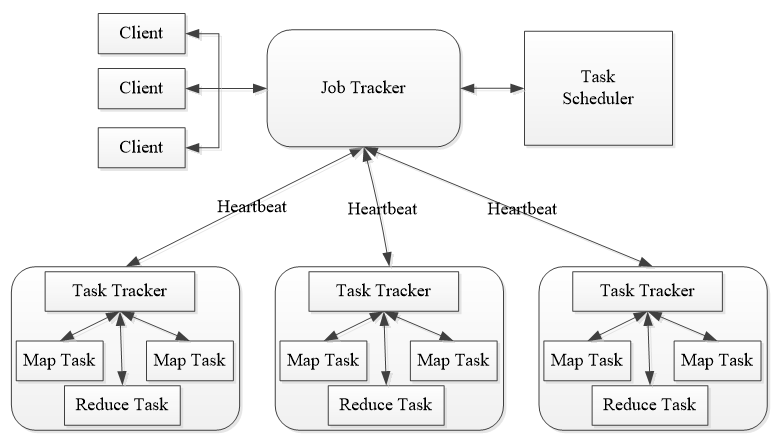

当运行大规模数据处理任务时,MapReduce框架是常用的解决方案之一,该框架允许将大任务分解为小任务并行处理,然后再将结果合并,以此提高处理速度和效率,在实际操作中,可能会遇到需要停止MapReduce作业的情况,本文旨在详细解析如何正确停止MapReduce作业,并探讨相关的最佳实践。
了解MapReduce的工作机制
MapReduce的核心思想是将大规模的数据计算任务分解为多个小任务,这些小任务在分布式系统中并行处理,MapReduce作业分为两个主要阶段:Map阶段和Reduce阶段,在Map阶段,原始数据被分割成小块,每一块都由一个Map任务处理,每个Map任务生成一组中间键值对,这些键值对经过排序和混洗后,作为输入传递给Reduce阶段,在Reduce阶段,Reduce任务根据键来处理数据,最终生成作业的输出。
停止MapReduce作业的标准流程
1. 查找作业ID:
要停止一个正在运行的MapReduce作业,首先需要确定作业的唯一标识符,即作业ID,这可以通过Hadoop作业列表命令实现,使用命令hadoop job list可以查看系统当前正在执行的所有作业及其ID。
2. 终止作业:
确定了要停止的作业ID后,接下来就是执行终止操作,使用Hadoop提供的命令hadoop job kill job_id可以杀掉指定的作业,如果作业ID是123456,那么命令将是hadoop job kill 123456。
常见问题与高级策略
1. 内存问题导致的作业卡住:

有时,MapReduce作业可能由于虚拟机或集群节点的内存不足而卡住,这种情况下,简单地杀死作业可能解决不了根本问题,需要检查并调整集群的资源分配策略,确保每个节点都有足够的内存来运行作业,优化MapReduce作业的配置,如调整Map和Reduce任务的数量,也可能有助于解决这一问题。
2. 通过管理工具停止作业:
在某些管理工具,如FusionInsight Manager中,停止MapReduce作业有其特定的操作路径,可以通过“集群 > 待操作的集群名称 > 服务 > Yarn”路径,找到相应的作业并停止它,这种方法适用于通过Web界面管理Hadoop集群的情境。
预防措施与最佳实践
为了避免频繁需要手动停止作业,建议在投入生产环境前对MapReduce作业进行充分的测试,包括测试数据的准确性和异常处理逻辑,合理配置集群资源,监控作业运行状态,可以有效减少作业失败或长时间挂起的情况。
高效管理与监控
为了更高效地管理MapReduce作业,建议使用一些自动化工具来监控作业状态,可以使用Apache Ambari这类工具来监控整个Hadoop集群,包括MapReduce作业的运行状态,定期对Hadoop集群进行维护和优化,如更新软件版本、替换硬件等,也能显著提高作业的成功率和稳定性。
相关问答FAQs
1. 如果作业没有响应,该如何排查问题?
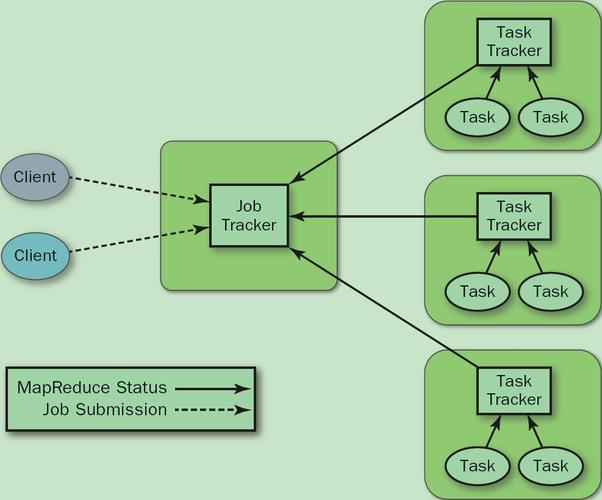
答:如果MapReduce作业没有响应,首先应检查集群的资源使用情况,包括CPU、内存和磁盘空间是否充足,查看作业日志,分析是否有代码错误或资源分配不当的问题,考虑网络状况是否影响到了作业的执行。
2. 如何避免在未来的作业中出现类似问题?
答:为了避免未来作业中出现类似问题,应该实施包括代码审查、压力测试在内的质量控制措施,建立完善的监控体系,及时捕捉并响应作业运行中的任何异常,持续优化集群配置和资源分配策略,确保每个作业都能获得足够的资源支持。
通过上述详细的步骤和策略,可以有效地管理和控制MapReduce作业,确保数据处理任务的顺利进行,在大数据时代,掌握这些技巧对于提高数据处理效率和准确性至关重要。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/890939.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复