

在当今互联网应用中,数据处理的需求愈发复杂和多样化,尤其是对数据库读写操作的要求,不仅需保证高可用性和一致性,还要应对高并发访问的挑战,Redis作为一款广泛使用的内存数据结构存储系统,支持多种灵活的数据模型,下面将深入探讨Redis读写分离实例的实现方式,以及通过一个具体例子来阐述其在处理大规模数据时的应用效果和优势:
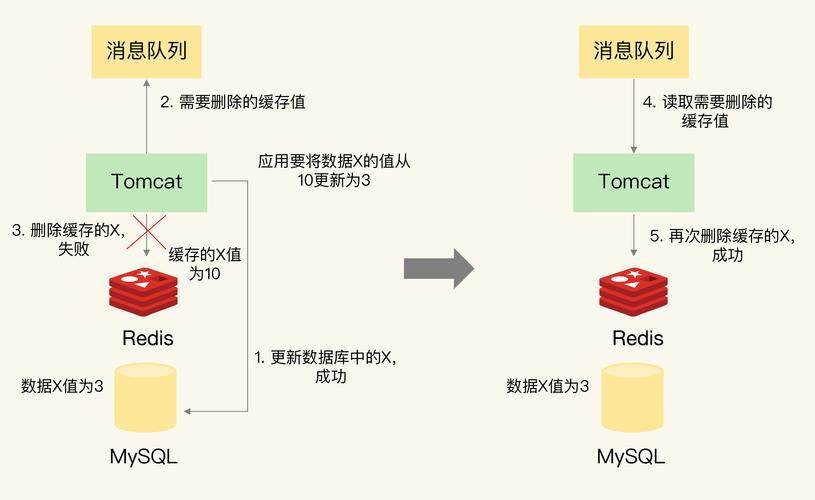
1、读写分离的基本架构
主从复制模式:Redis读写分离基于主从复制(masterreplica)模式,其中主节点处理写操作,而从节点则负责读操作,这种分离确保了即使面临大量请求,系统仍能保持高效的性能。
链式复制架构:Redis采用链式复制架构,可以通过增加只读实例的数量来线性扩展整体实例的性能,充分利用每个只读节点的物理资源。
2、读写分离的关键组件
Proxy组件:阿里云Tair团队自研的Proxy组件在读写分离架构中起到关键作用,负责数据分发、故障切换等服务。
异步复制持久化方案:Redis默认采用异步复制的持久化方案(RDB),这是其自然复制模式,有助于实现低延迟和高性能。
3、读写分离的应用场景
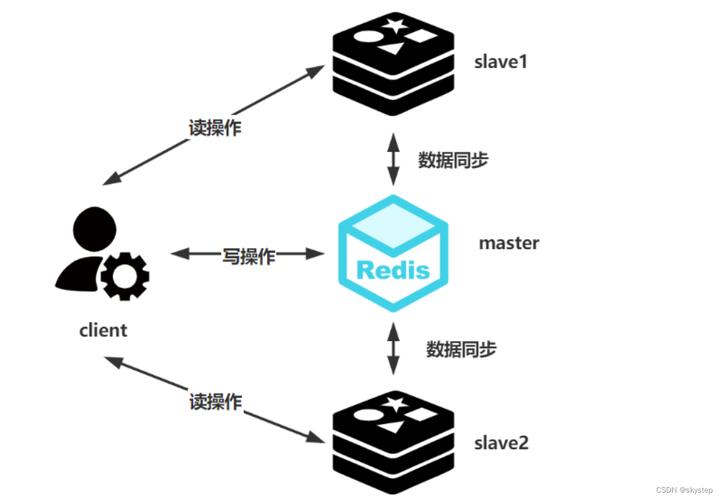
高并发读取需求:对于读多写少的业务场景,如热点数据集中及高并发读取的业务需求,Redis读写分离提供了高可用和灵活的服务。
扩展服务能力:通过扩展只读实例个数,使整体实例性能线性增长,可有效应对读取请求QPS压力较大的情况。
4、读写分离的技术细节
实例规格选择:读写分离实例的规格包括内存容量、连接数、带宽、QPS参考值等,选择合适的实例规格是确保性能的关键。
资源分配策略:为保障服务稳定运行,系统中每个节点都会保留一定的CPU核心用于后台任务处理,这对于集群或读写分离架构尤为重要。
5、读写分离的优势对比
性能优化:通过分散读写操作到不同的节点,可以显著提升数据处理的效率,尤其是在数据密集型的应用中。
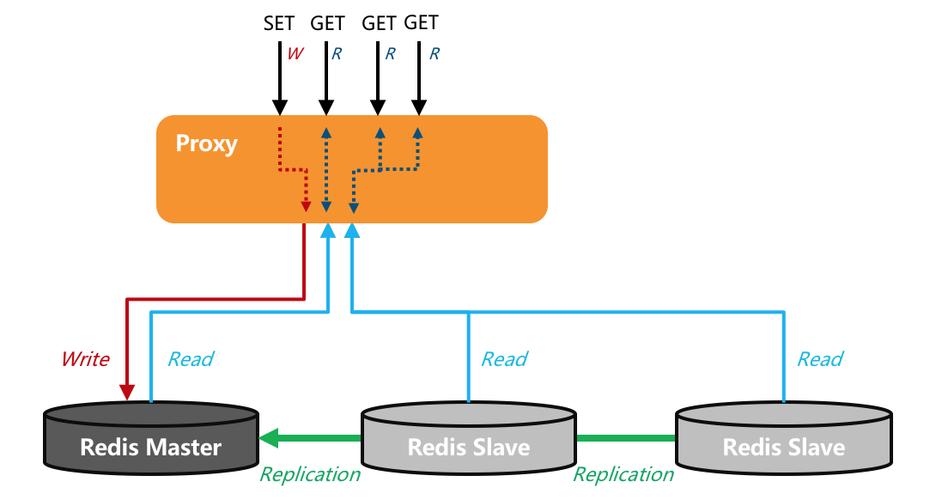
成本效益:相比于采用单一的大型机处理所有请求,读写分离能够更经济地扩展系统的处理能力。
Redis读写分离实例通过优化资源使用和增强数据处理能力,为现代高并发、数据密集型的应用提供了一个高效、可靠的解决方案,准确的资源配置和有效的故障切换机制也是确保这一架构成功实施的关键因素,通过这些综合措施,Redis读写分离功能不仅满足了业务需求,还提升了系统的整体性能和稳定性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/890849.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。

发表回复