


MapReduce算法实例:表关联
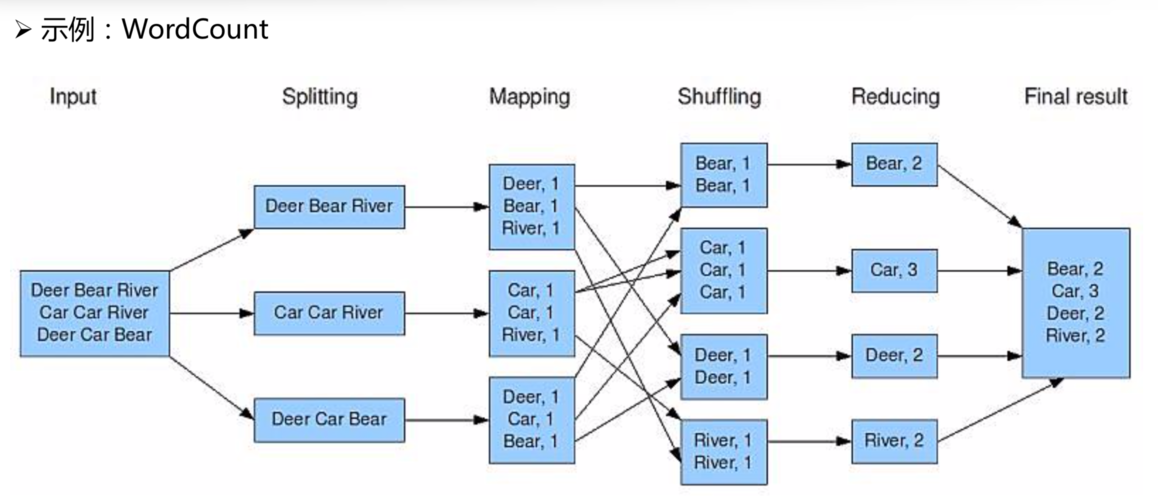

MapReduce是一个分布式运算程序的编程框架,它通过将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上,下面通过一个简单的实例来展示如何使用MapReduce进行数据处理。
基本概念
MapReduce的核心思想是将大规模数据集操作分拆成两个阶段:Map和Reduce,在Map阶段,计算被分布到多个节点上执行;在Reduce阶段,各个节点的结果被汇总处理以得到最终结果,这种模型适合处理大量数据,并且可以通过增加更多节点来提高处理能力。
环境设置
为了运行MapReduce程序,需要设置Hadoop环境,如果您不喜欢自己搭建Hadoop环境,可以下载使用本教程提供的环境,实践部分内容中会介绍具体使用方法。
实例描述
假设有两张表:部门信息(DEP.txt)和员工信息(EMP.txt),部门信息包括部门编号和部门名称,员工信息包括员工姓名、性别、年龄和部门编号,我们的任务是将这两张表按照部门编号关联起来,形成一张新的表。
Map阶段的实现
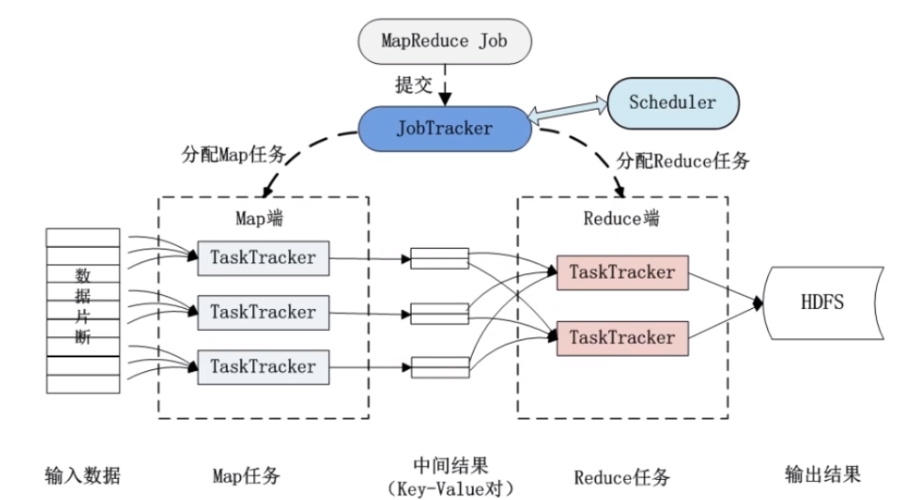
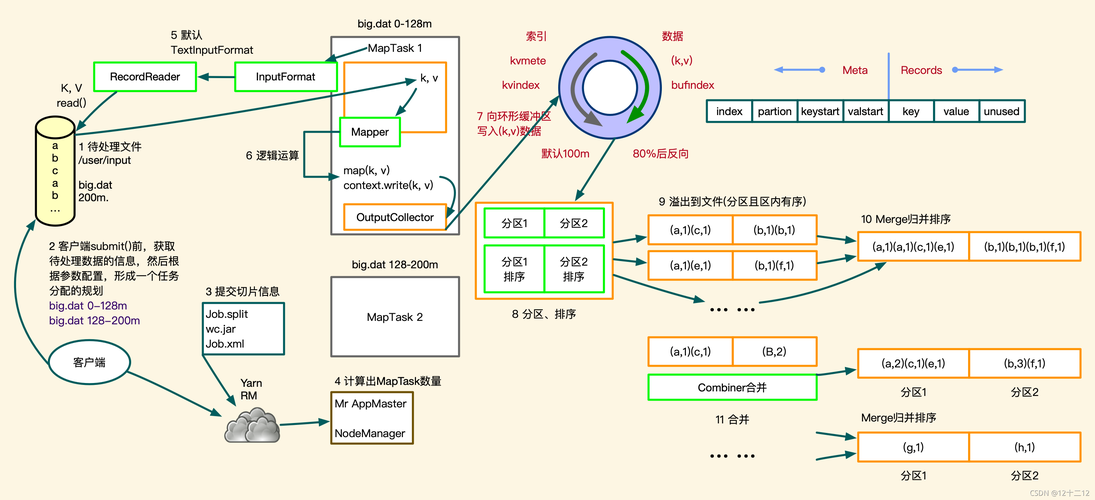
在Map阶段,输入的数据文件被分割成小块,每一块由一个Map任务处理,每个Map任务读取一块数据,解析每一行记录,然后将关键字(部门编号)和值(部门名称和员工信息)输出。
Shuffle and Sort阶段
这个阶段是MapReduce框架自动完成的,输出的键值对被排序并根据键进行分组,使得具有相同键的值被集中到一起。
Reduce阶段的实现
在Reduce阶段,每个Reduce任务接收到一个键及其对应的所有值的集合,在这个例子中,Reduce函数将遍历所有的员工信息,并将其与相应的部门名称合并,输出最终的关联结果。
通过上述过程,MapReduce成功实现了数据的关联操作,这显示了其在处理大数据集方面的强大能力,尽管这个例子相对简单,但它揭示了MapReduce处理大规模数据的基本思路。
相关问答FAQs
Q1: MapReduce程序如何保证数据处理的正确性?
A1: MapReduce框架通过严格的顺序和数据流控制来确保数据处理的正确性,在Map阶段,数据被分割并处理;在Shuffle and Sort阶段,数据被排序和分组;最后在Reduce阶段,数据被最终汇总,框架还提供了容错机制,即使在硬件故障的情况下也能保证计算的正确性。
Q2: 如何优化MapReduce程序的性能?
A2: 优化MapReduce程序性能可以从以下几个方面考虑:合理设置数据块大小和Map、Reduce任务的数量;尽可能减少网络传输的数据量;优化数据序列化和反序列化的方法;充分利用Hadoop集群的资源,比如通过调整内存配置和并发执行设置来提高资源利用率。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/890750.html
 微信扫一扫
微信扫一扫