

在大数据技术中,MapReduce框架是处理大规模数据集的关键工具之一,MapReduce模型将数据处理分为两个步骤:Map步骤和Reduce步骤,而在数据准备阶段,数据截断即数据切片(Splitting)是至关重要的一环,数据切片确保了MapReduce能够高效并行处理大量数据,本文将深入探讨MapReduce中的数据截断机制,包括切片对象、切片过程及其对性能的影响。
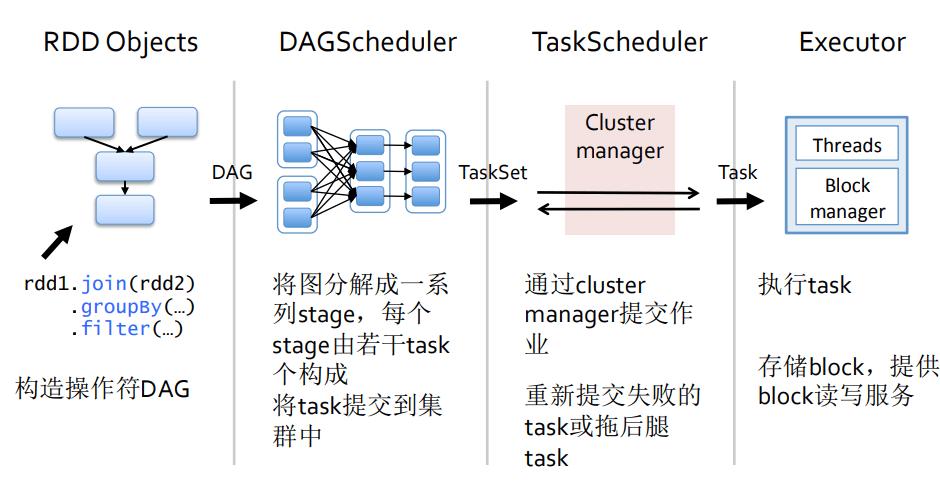
数据切片基础
MapReduce作业的数据切片是将输入数据分割成多个小块的过程,这些小块将由不同的Map任务处理,每个切片对应一个Map任务,而切片的大小通常与Hadoop中的块大小相等,默认为128MB或由用户配置决定,这种设计允许MapReduce框架有效利用集群资源,实现数据的并行处理。
切片机制和任务提交流程
在Hadoop中,文件的切片机制相对简单但极为重要,系统默认将文件按照其长度简单切分,每次切分后,如果剩余部分不大于块大小的1.1倍,则将其归入上一个切片,值得注意的是,切片过程是针对每一份文件单独进行的,这意味着不同文件的切片大小可能不同。
任务提交流程开始于客户端Driver通过job.waitForCompletion()和submit()方法提交任务,这个过程包括建立到集群的连接,并判断是本地Yarn还是远程Yarn,然后创建用于提交Job的代理,这一序列操作确保了MapReduce作业能够在分布式环境中顺利执行。
MapTask的合理设置
尽管更多的MapTask似乎意味着更好的并行度和可能的性能提升,事实却并非如此,适量的MapTask是关键,因为对于小数据集(如1KB数据),使用多个MapTask反而可能导致任务启动时间超过数据处理时间,适得其反,合理设置MapTask的数量,根据数据量调整MapTask的并行度是非常必要的。
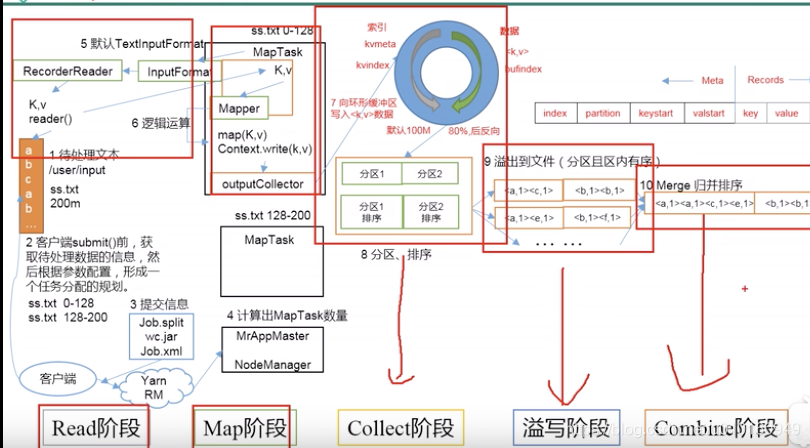
分区和自定义输出
进一步地,MapReduce允许用户根据具体需求进行数据分区,并在处理过程中自定义输出,可以编写一个MapReduce任务,首先识别所有的产品名称,然后在第二个MapReduce任务中,按产品名称对数据进行分区,这样的自定义多输出,使得数据处理更加灵活和高效。
性能优化建议
要优化MapReduce作业的性能,关注数据切片的策略是重要的,合理选择切片大小和确保数据均匀分布能够显著影响作业的执行时间,避免产生过多的小切片可以减少开销,提高整体处理速度。
相关FAQs
Q1: 如何确定MapReduce作业中的最佳MapTask数量?
A1: MapTask的数量应基于输入数据的大小和结构来确定,考虑每个任务处理的数据量应接近但不超过HDFS的块大小(通常是128MB),对于小数据集,较少的MapTask更为高效,可以使用工具预测并调整MapTask数量以达到最优性能配置。
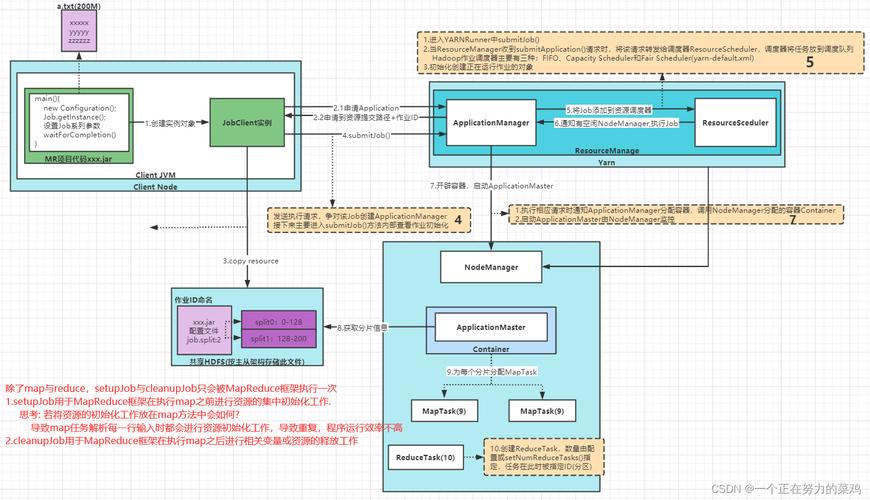
Q2: 数据切片不均匀会如何影响MapReduce作业的性能?
A2: 如果数据切片不均匀,某些MapTask可能会处理比其他任务更多的数据,导致负载不均衡,这种情况可以引起个别任务运行时间延长,从而拖延整个作业的完成时间,确保数据尽可能均匀切片,可以提升处理速度和资源利用率。
通过以上分析可以看出,MapReduce中的数据截断是一个关键步骤,它直接影响到后续Map和Reduce任务的执行效率,理解并合理配置数据切片及其相关参数,对于实现高效的数据处理至关重要。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/890545.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复