


1、MySQL数据库引擎类型
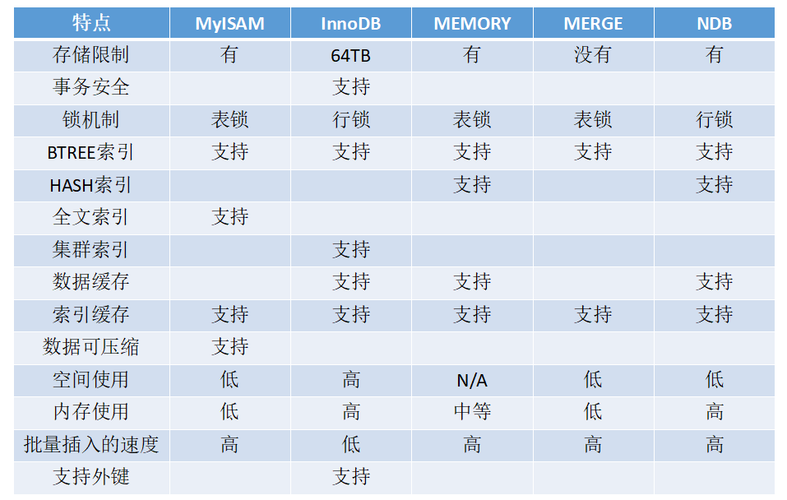

InnoDB:InnoDB引擎支持ACID事务特性,确保数据库操作的完整性和一致性,它通过行级锁定和外键约束,提高了并发性能并确保数据的完整性,适用于需要高事务的环境。
MyISAM:MyISAM引擎提供高速的存储和检索能力,支持全文搜索,适用于只读或大量读操作的场景,但需要注意的是,MyISAM不支持事务处理,因此在需要事务支持的应用中并不适用。
MEMORY (HEAP):MEMORY引擎用于创建内存中的临时表,由于数据保存在内存中,其访问速度非常快,但一旦服务器重启,所有数据将会丢失,这适用于存储临时结果集或快速访问的小数据集。
MERGE:MERGE引擎允许将多个MyISAM表的集合作为一个单独的表来处理,这对于联合多个相似的表以提高效率和查询性能非常有用,尤其适合数据仓库和日志记录系统。
ARCHIVE:ARCHIVE引擎主要用于存储大量的归档数据,支持高效的插入和查询操作,适用于数据仓库和历史数据存储,但其不支持索引和修改操作。
CSV:CSV引擎将数据以逗号分隔的形式存储在文本文件中,这使得可以直接使用文本编辑器查看和处理数据,适用于需要与其他软件系统(如电子表格软件)交换数据的应用场景。
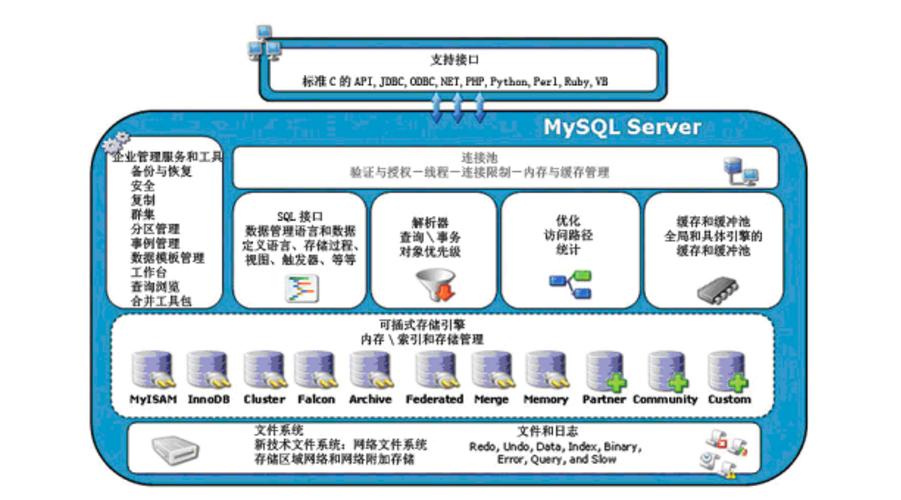
2、采样方式种类
随机采样:随机采样是从数据集中随机选择样本的方法,可分为随机过采样和随机欠采样,随机过采样通过重复少数类样本来平衡数据集,而随机欠采样则是通过减少多数类样本来避免数据偏差。
池化和步长卷积:在深度学习中,池化是一种常用的下采样方法,通过降低特征维度来减少计算量,同时保留重要信息,步长为2的卷积操作也可以实现类似的下采样效果,通过增大步长来减少输出的分辨率。
插值、反池化和反卷积:这些是深度学习中常见的上采样方法,插值通过数学方法增加数据点的密度,反池化和反卷积则通过逆操作还原数据至原始或更高分辨率,常用于图像处理和生成任务中。
基于线性插值的上采样:包括最近邻算法、双线性插值算法和双三次插值算法等,这些方法通过不同的算法逻辑对原有数据点进行扩充,实现从低分辨率到高分辨率的转换。
基于深度学习的上采样技术:例如转置卷积、PixelShuffle和其他高级插值方法,利用深度学习模型对特征进行上采样,常用于提高图像分辨率或生成高清图像。
FAQs
Q1: 如何选择适合的MySQL存储引擎?
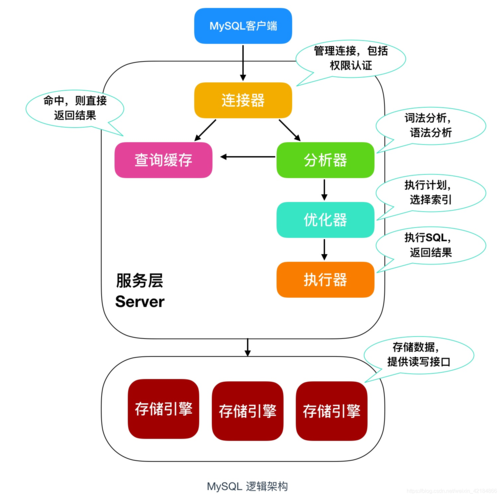
A1: 选择MySQL存储引擎时应考虑应用的需求,如果应用需要事务支持,InnoDB是最佳选择;若应用读取频繁且不需要事务,可以选择MyISAM;对于需要快速访问的临时数据,MEMORY引擎是一个好选择;而对于大量相似MyISAM表的集合,使用MERGE引擎可以提高查询效率。
Q2: 数据采样方法在哪些领域最常用?
A2: 数据采样广泛应用于机器学习和数据分析领域,特别是在处理大规模数据集时,通过采样可以有效减少数据处理时间和计算资源消耗,在图像处理和视频游戏开发中,上采样技术常用于提升图像分辨率和质量。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/890175.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复