


MapReduce和Spark都是大数据处理框架,广泛应用于数据处理与分析,它们在模型、存储和性能优化等方面有所不同,具体分析如下:

1、模型
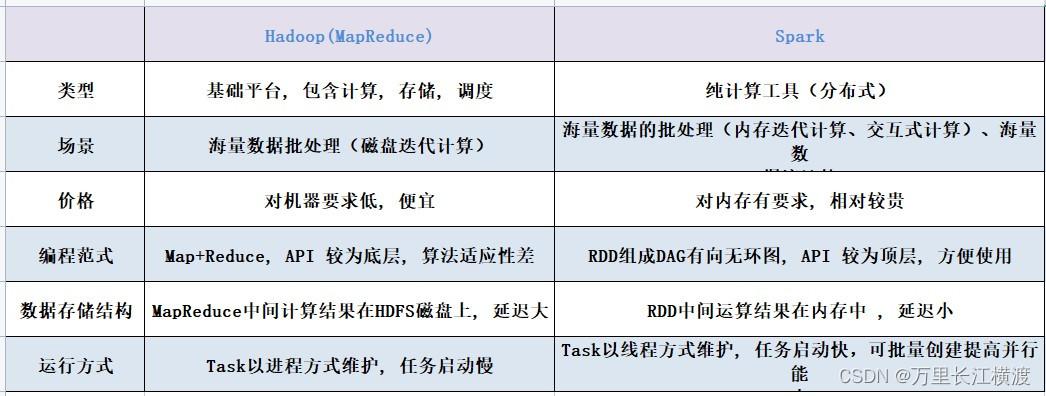
MapReduce:基于磁盘的批量处理,每次操作后都将数据写入磁盘,再读取,进行下一个操作。
Spark:支持流批处理,可以在内存中执行多次迭代式计算,尤其适合低延迟、迭代运算类型作业。
2、存储
MapReduce:频繁读写磁盘,减轻内存压力,但降低了计算性能。
Spark:基于内存计算,中间结果可保存在内存中反复利用,显著提高处理速度,支持将数据以列式形式存储于内存中,如SparkSQL,进一步优化查询性能。
3、性能优化
MapReduce:传统的MapReduce模型在数据处理时会多次读写磁盘,即数据在Map阶段写完一次磁盘,Reduce阶段再读一次磁盘,导致I/O开销较大。
Spark:通过构建DAG(有向无环图),Spark能够减少shuffle和数据落地磁盘的次数,优化性能,在内存计算方面,Spark比MapReduce快,根本原因在于其DAG计算模型,减少了不必要的磁盘IO操作。
4、容错机制
MapReduce:容错性较强,通过将中间结果写入磁盘,可以容易地从失败中恢复。
Spark:支持checkpoint,可以将数据集和RDD的计算状态保存到可靠的存储系统中,以便从节点失败中快速恢复。
5、资源利用
MapReduce:每个Map或Reduce任务都由独立的JVM进程运行,资源隔离但利用率较低。
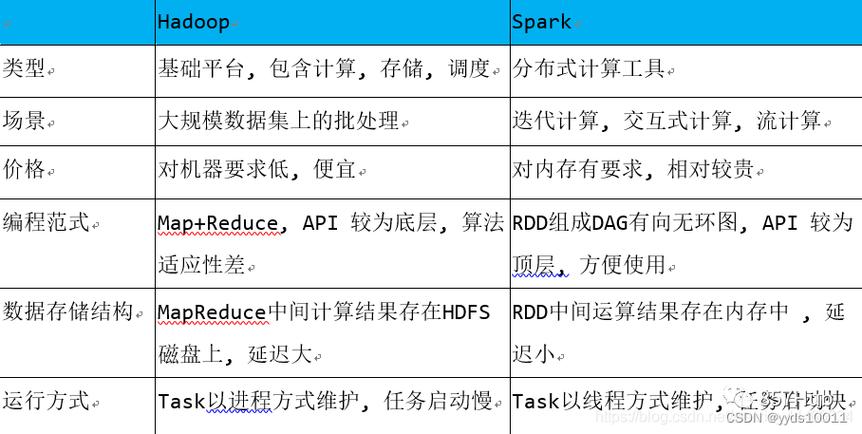
Spark:多线程模型,每个worker节点可以运行一个或多个executor服务,每个task作为线程在executor中运行,能够共享资源并提高资源利用率。
6、适用场景
MapReduce:适合简单的批量数据处理,对于不需要频繁迭代的数据分析较为合适。
Spark:由于其内存计算特性,非常适合于需要快速迭代的机器学习和图计算等场景。
针对上述分析,提出以下几点建议:
在选择框架时,考虑数据的规模和处理需求。
考虑团队的技术栈和经验,选择最熟悉的工具以提升开发效率。
评估硬件资源,尤其是内存大小,以确定是否适合运行Spark。
如果追求的是高性能和快速的数据处理,尤其在机器学习和图形处理领域,Spark无疑是更优的选择,对于初学者或者对实时性要求不高的场合,MapReduce由于其简单和容错性好仍然是一个不错的选择。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/890046.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复