


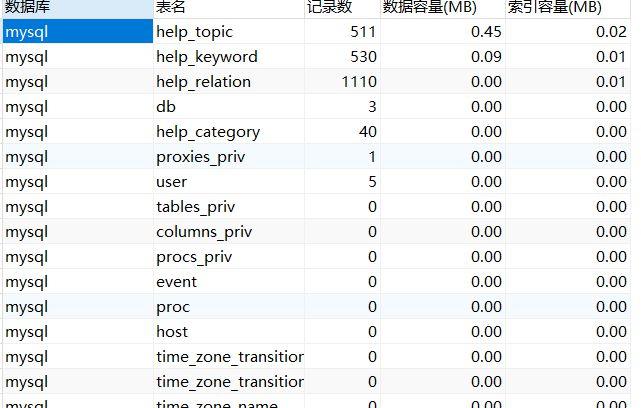
在今天的大数据环境中,有效地加载和管理数据是至关重要的,Apache CarbonData是一个开源的高性能列式存储解决方案,专门用于快速数据分析和数据探索,将深入探讨如何将数据加载到MySQL中的CarbonData表,包括一系列步骤和考虑因素。

基本概念和准备工作
在使用CarbonData前,需要理解其基本的数据加载概念,CarbonData支持加载历史数据和增量加载新数据,这对于实时数据分析非常有帮助,该工具提供了优化的资源使用和查询性能,通过特有的索引结构,可以显著加快数据查询速度,并减少资源消耗。
在开始加载数据之前,确保所需的数据文件已经准备好,并且符合CarbonData的格式要求,这些文件通常是CSV格式,但也可以是从其他系统如Hive或Parquet表中导出的数据。
上传文件到HDFS
CarbonData通常与HDFS(Hadoop分布式文件系统)配合使用,以处理大规模数据集,加载数据的第一步通常是将数据文件上传到HDFS,这一步骤可以通过Hadoop提供的命令行工具完成,如使用hadoop fs put命令将本地文件上传到HDFS,一旦文件上传到HDFS,便可以通过Spark或其他大数据处理框架对其进行处理。
创建CarbonData表
在数据加载之前,需要在MySQL中创建一个CarbonData表,用于存储即将加载的数据,这可以通过编写SQL语句来完成,指定表的结构包括各列的名称和数据类型。
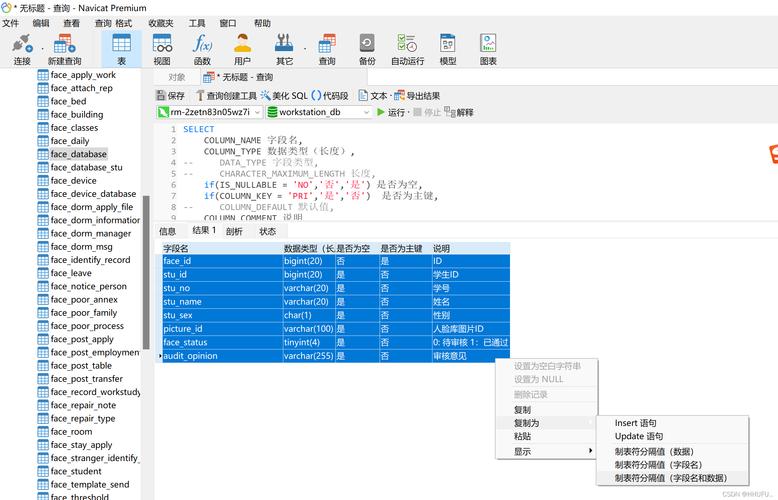
CREATE TABLE carbondata_table_name (
column1_name data_type,
column2_name data_type,
...
) STORED AS carbondata; 数据加载命令
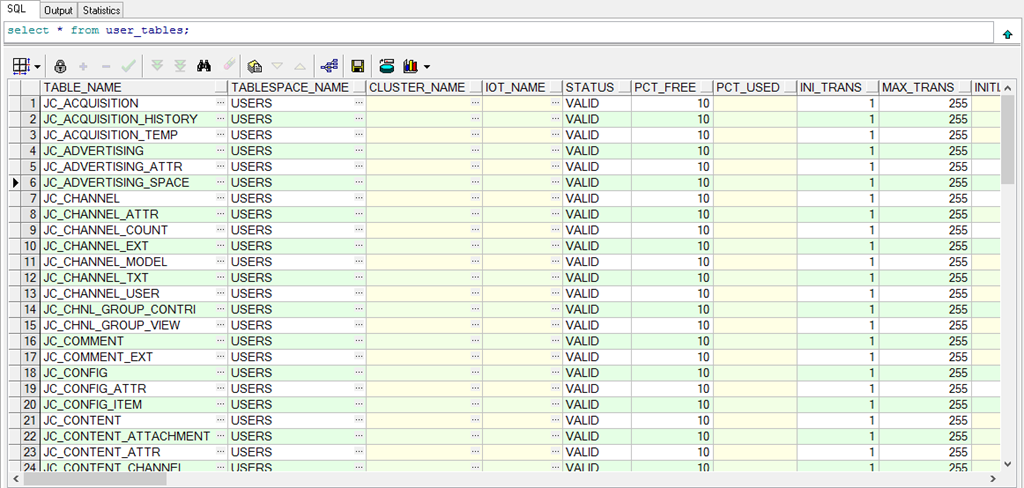
使用LOAD DATA命令将数据从HDFS加载到前面创建的CarbonData表中,这个命令有多个选项,如设置字段分隔符、引用字符等,可以根据数据文件的具体格式进行调整。
LOAD DATA INPATH 'hdfs_path/your_data_file.csv' INTO TABLE carbondata_table_name OPTIONS ( 'DELIMITER' = ',', 'QUOTECHAR' = '"', 'FILEHEADER' = '0', 'ESCAPECHAR' = '\', 'MULTILINE' = 'false' );
这里,INPATH指定了HDFS中数据文件的路径,而OPTIONS则根据数据文件的特性设定了相应的参数,以确保数据正确解析和加载。
数据验证和调整
数据加载完成后,应进行验证以确保所有数据都正确载入,这可以通过简单的查询操作来实现,比如检查表中的行数是否与原始数据文件匹配,CarbonData支持数据的增量加载和更新,这意味着用户可以定期将新数据添加到表中,保持数据的时效性和准确性.
在实际操作中,可能需要对性能进行调优,例如调整索引设置或查询参数,以适应特定的查询模式和数据访问需求,CarbonData提供的详细文档和社区支持可以帮助用户进行这些高级操作。
通过上述步骤,用户可以有效地将数据加载到MySQL的CarbonData表中,利用CarbonData的强大功能进行数据分析和处理。
相关问答FAQs
Q1: 如何在已有的CarbonData表上加载更新的数据?
A1: 可以使用增量加载的方式添加新数据到现有的CarbonData表中,首先确保新的数据文件遵循相同的格式和结构,然后使用LOAD DATA命令指定新增数据的HDFS路径,并将其加载到目标表中,利用CarbonData的时间戳或标识列来管理新旧数据的关系。
Q2: 如何处理加载过程中遇到的错误?
A2: 加载过程中可能会遇到各种问题,如格式错误、数据不匹配等,检查LOAD DATA语句中的OPTIONS部分,确保其正确设置了字段分隔符、引用字符等,确认数据文件在HDFS上的路径是正确的,查看CarbonData的错误日志获取详细的错误信息,并根据错误提示调整数据文件或加载命令。
通过以上步骤和技巧,可以有效地管理和解决在数据加载过程中可能遇到的问题,确保数据能够准确无误地载入到CarbonData表中。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/889104.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复