


MapReduce和Spark在Hortonworks HDP上对接OBS的差异分析

MapReduce和Spark是大数据处理框架的两种不同选择,它们在处理数据密集型任务时有着各自的特点和优势,本文将深入探讨这两种计算模型在与华为云对象存储OBS (Object Storage Service) 对接时的不同点,特别是在使用Hortonworks Data Platform (HDP) 时的实际应用情况。
MapReduce 的对接过程及特点
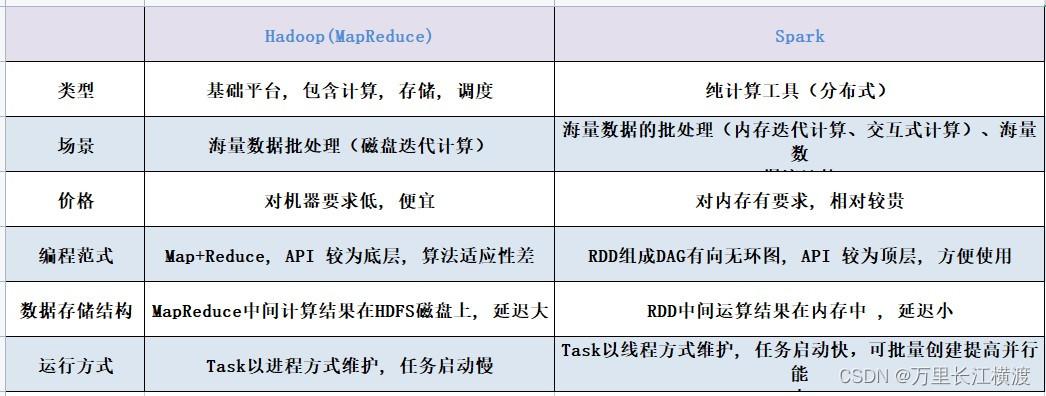
MapReduce是传统的大数据计算模型,它在处理大规模数据集时展现出了强大的稳定性和可靠性,在HDP平台上,MapReduce通常与HDFS(Hadoop Distributed File System)紧密集成,用于处理批量数据处理任务,对接OBS时,需要通过增加特定的配置项和使用OBSFileSystem组件来实现数据在OBS的读写操作。
配置和部署:在MapReduce2集群中增加配置项,这包括下载并更新与Hadoop版本配套的OBSAHDFS工具,这些操作确保了MapReduce能够无缝地与OBS进行数据交换。
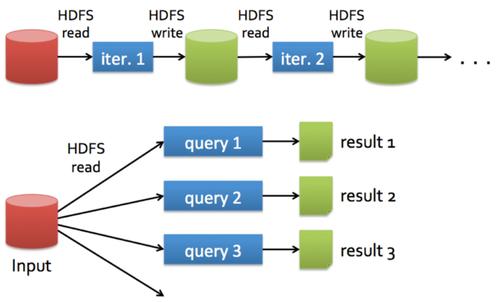
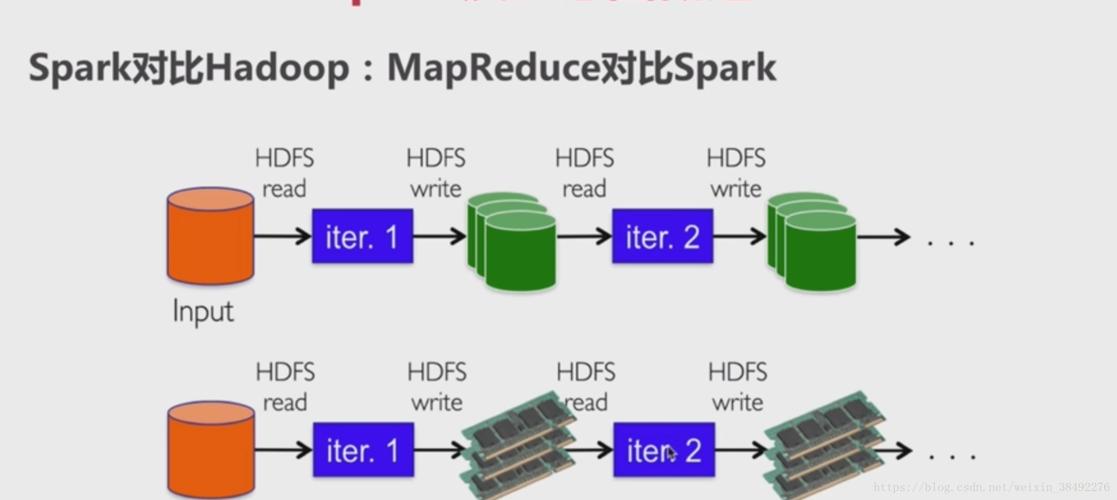
性能优化:由于MapReduce的设计是基于磁盘的计算模型,其中间结果需要写入到磁盘,这在处理大量迭代计算如机器学习任务时可能会遇到性能瓶颈。
适用场景:MapReduce适合于批量处理和非迭代的大数据处理任务,例如日志分析、ETL操作等。
Spark 的对接过程及特点
Spark是一个较新的大数据处理框架,它的核心优势在于基于内存的计算模型,这使得它在处理需要迭代计算的算法时表现出高效率,Spark的部署和配置在对接OBS时也显示出其独特的优势。
部署和配置差异:相对于MapReduce, Spark不需要大量的磁盘读写操作,因此可以更高效地与OBS进行数据交互,Spark的配置主要侧重于优化内存使用和网络传输效率。
性能优化:Spark通过其RDD(弹性分布式数据集)API提供了一套高效的容错机制,允许任务在失败时快速恢复,而无需重复进行大量的数据读写操作。
适用场景:Spark特别适用于需要快速迭代的数据挖掘和机器学习任务,例如图计算、实时数据分析等。
OBS对接的实际应用比较
在对接OBS方面,MapReduce和Spark虽然都可以通过OBSFileSystem组件实现数据的存储和访问,但在实际应用场景中存在一些差异,Spark由于其内存计算的特性,更适合于处理高速流数据和实时分析任务,而MapReduce则更适合处理静态数据集的批量操作。
当涉及到在HDP平台上使用华为云OBS时,用户应根据自己的具体需求选择合适的计算框架,如果业务需求中包含大量的实时数据处理或需要频繁迭代的计算任务,Spark可能是更优的选择;而对于大规模的批处理任务,MapReduce则可能更加适合。
了解MapReduce和Spark在对接OBS时的差异不仅有助于优化数据处理流程,还可以帮助企业根据具体的业务需求做出更合适的技术选择,通过合理利用这两种技术的优势,企业可以更好地管理和分析大数据,从而为决策提供支持,推动业务发展。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/888519.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复