

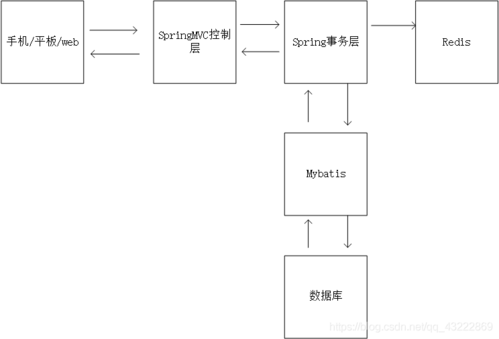
在当今大数据时代,对于海量数据的处理需求日益增长,MapReduce作为分布式计算的一种编程模型,非常适合进行大规模数据集(大于1TB)的运算,常与分布式数据库Redis结合使用以提升数据处理效率,将详细探讨MapReduce关联Redis支持的资源关系,深入理解二者如何协同工作,优化数据处理流程:

1、MapReduce模型基础
概念理解:MapReduce包括"Map(映射)"和"Reduce(归约)"两个主要步骤,分别对应于数据的分解和结果的聚合,这种模型允许任务在分布式系统中并行处理,极大提高了数据处理速度。
工作原理:在Map阶段,输入数据被分割成独立的数据块,由Map函数处理产生中间键值对;在Reduce阶段,根据键值对的键进行排序和分组,交由Reduce函数处理得到最终结果。
2、Redis的作用
数据存储:Redis作为一个高性能的NoSQL数据库,常用于缓存和持久化存储键值对数据,特别适合存储MapReduce过程中的中间状态和最终结果。
优势特性:Redis支持多种数据结构,如字符串、哈希、列表、集合、有序集合等,且具有高吞吐量、低延迟的特点,非常符合MapReduce处理过程中对数据快速读写的需求。
3、Redisson客户端
功能介绍:Redisson是Java编程语言的一个流行的Redis客户端,提供了丰富的API和服务,例如分布式对象、集合、锁和同步器等,为Java程序操作Redis提供了极大的便利。
MapReduce支持:通过Redisson客户端,可以在Redis中直接执行MapReduce任务,利用其提供的分布式实现,简化数据处理过程并提高性能。
4、集成实践
连接池管理:在Java环境中,可以通过维护一个Jedis连接池来有效地管理与Redis的连接,这有助于节约资源并提高数据处理效率。
输出优化:重写FileOutputFormat并创建RedisRecordWriter可以高效地将MapReduce任务的处理结果写入到Redis中,这是数据库记录输出的关键一环。
5、应用示例
示例:具体示例,如计算Redis中存储文本数据的字数,展示了如何使用Java和Redisson实现基于Redis的MapReduce,从而加速数据处理过程。

实现细节:在该示例中,Map阶段统计各节点数据的字数,Reduce阶段则将所有节点的结果汇总起来,得到最终的字数总计。
深入掌握MapReduce和Redis的联合使用,不仅需要了解它们的基本概念和操作方式,还需注意以下几个方面:
合理设计Map和Reduce函数,确保数据的高效处理。
优化Redis的数据结构和访问模式,充分利用其性能优势。
考虑使用像Redisson这样的客户端工具简化开发过程,提高代码的可维护性和性能。
MapReduce与Redis的结合为大规模数据处理提供了一种高效的解决方案,通过利用Redis的高性能数据存取能力和MapReduce的分布式计算框架,可以显著加快数据处理速度,优化资源使用,在实际开发过程中,应充分考虑数据处理需求和系统架构的匹配,选择合适的工具和方法,以达到最优的性能表现。
FAQs
如何在Java中使用Redis和MapReduce处理大规模数据?
在Java中使用Redis和MapReduce处理大规模数据,首先需要引入像Redisson这样的Redis客户端库,然后根据数据处理需求编写相应的Map和Reduce函数,可以使用Redisson提供的分布式编程模型直接在Redis数据上执行MapReduce任务,同时利用Java的并发和连接池管理机制来优化数据处理过程。
MapReduce在处理Redis数据时有哪些注意事项?
在使用MapReduce处理Redis数据时,需要注意数据分片、并行处理策略以及网络带宽等因素,确保Map函数能均匀处理数据分片,避免数据倾斜问题,Reduce阶段的并发度设置也非常关键,过高或过低都可能影响整体性能,由于数据传输量可能很大,确保网络带宽足够以避免成为瓶颈。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/888419.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复