


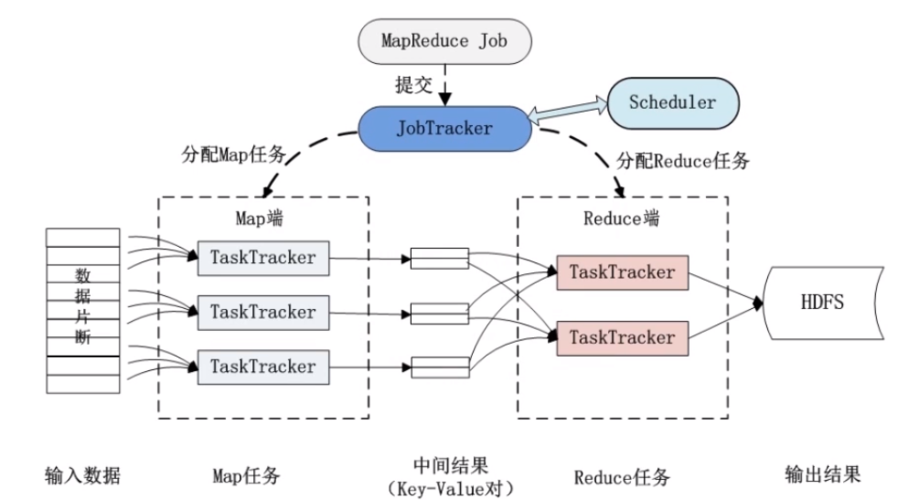
在当今大数据时代的浪潮中,处理大规模数据集已成为技术发展的一个重要方向,MapReduce模型,由Google提出并广泛运用于海量数据处理,极大地促进了分布式计算的发展,MapReduce的核心在于两个基本阶段:Map和Reduce,Map负责数据的分割和初步处理,而Reduce则进行数据的汇总与输出,本文将重点探讨Map阶段的打散操作,分析其重要性及实现方式。
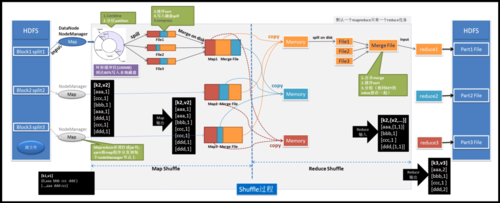

在MapReduce框架中,Map阶段的主要任务是将输入的大规模数据划分为多个小数据块,每个数据块分别由不同的Map任务处理,每个Map任务会处理分配给它的数据,并生成一系列中间键值对(keyvalue pair),这些中间结果会被送到Reduce阶段,由Reduce任务根据key进行汇总处理,此环节关键在于如何高效地将Map阶段的输出传递到Reduce阶段,保证负载均衡以及减少数据处理的延时。
Map阶段的打散操作
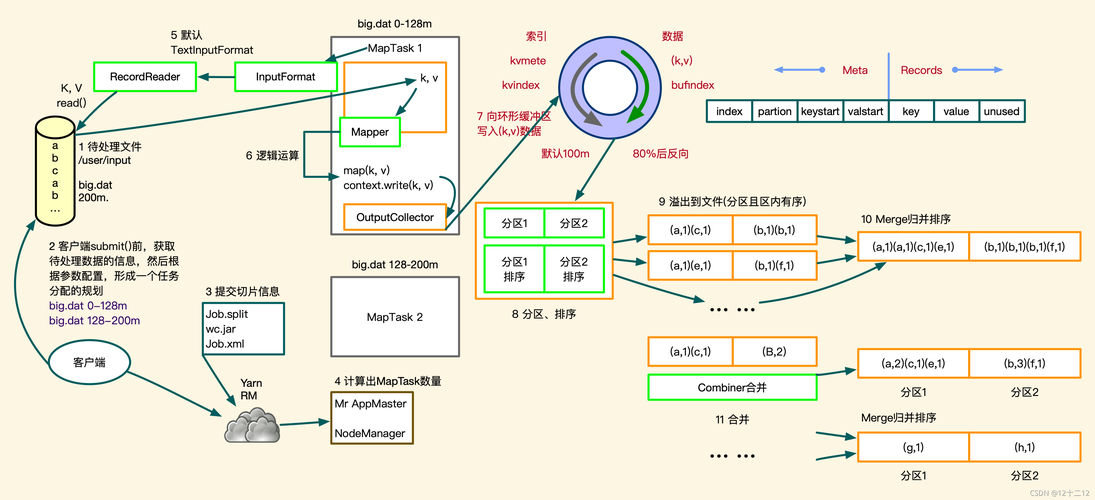
Map阶段的打散操作是确保数据均匀分布的关键步骤,在实际操作中,如果简单地按原始数据的分区来处理,常常会导致数据倾斜问题,数据倾斜是指某些节点被分配到的数据量远大于其他节点,造成部分节点过载而影响整体的处理速度,解决这一问题的一个有效方法是实施key的打散操作,即通过某种策略重新分配key,使得相关的数据能更均匀地分配到各个Reduce节点上。
打散操作的实施方法
1、预设分区: MapReduce框架允许用户自定义分区策略,通过修改hash函数或定义特定的分区逻辑,可以实现key的更合理分配。
2、增加Reduce任务的数量: 提高并行度,可以在一定程度上缓解单个节点的压力。
3、使用随机key: 对于某些特定应用,可以使用随机key来避免大量数据集中到少数节点。
代码实例
假设我们使用Hadoop平台进行MapReduce编程,可以通过以下方式实现自定义分区:
public class CustomPartitioner extends Partitioner<Text, IntWritable> {
@Override
public int getPartition(Text key, IntWritable value, int numReduceTasks) {
// 自定义分区逻辑
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
} 在MapReduce的设置中,通过设置job.setPartitionerClass(CustomPartitioner.class)来启用自定义分区。
打散操作的重要性
打散操作不仅有助于减轻数据倾斜的问题,还可以优化整个MapReduce作业的性能,合理的数据分配可以使所有节点都能高效运作,缩短作业完成的时间,同时减少因数据倾斜可能导致的节点故障风险,通过打散操作,可以更好地利用网络带宽,平衡数据传输的负载,从而提高整个系统的吞吐量和响应速度。
相关FAQs
1. MapReduce中的打散操作是否会影响数据的完整性?
不会影响,打散操作只是改变了数据在Reduce阶段的分配方式,不会改变数据本身的内容和结构,它确保了每个Reduce任务都能接收到完整的数据子集,从而正确地完成数据的汇总和计算。
2. 实施打散操作后,是否还需要其他优化措施?
是的,除了打散操作外,还可以通过其他多种方式优化MapReduce任务的性能,例如使用Combiner减少数据传输量、选择合适的序列化方式减少磁盘和网络I/O负担等,这些措施通常需要根据具体的应用场景和数据特性来综合考虑。
Map阶段的打散操作是MapReduce模型中一个至关重要的步骤,它直接关系到数据处理的效率和系统的稳定性,通过合理的设计和配置,可以显著提升MapReduce作业的整体表现,更好地应对大规模数据处理的挑战。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/888375.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复