



在数字化时代,内容安全文本检测成为了保障网络环境健康、维护用户权益的重要手段,它通过技术手段识别和过滤不良信息,保护用户不受有害内容的侵害,同时也帮助企业遵守相关法律法规,减少法律风险。
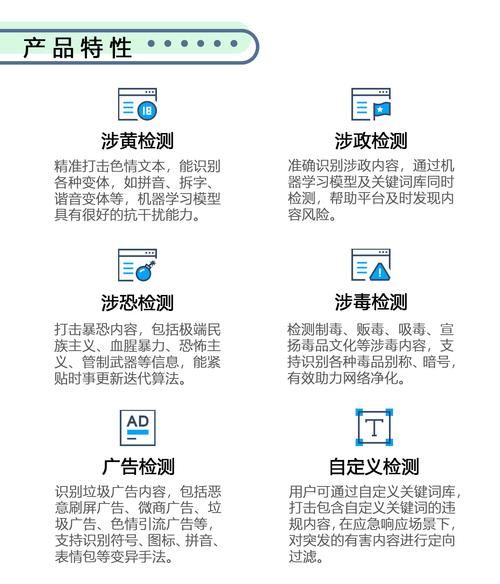
核心功能
1、敏感词汇检测:识别并过滤掉涉及色情、暴力、恐怖等敏感词汇。
2、恶意链接识别:检测文本中是否含有指向恶意软件或钓鱼网站的链接。
3、广告与垃圾信息筛选:区分正常信息与垃圾广告,提升用户体验。

4、版权保护:检测是否有侵犯知识产权的内容存在。
5、声誉风险管理:预防和处理可能损害企业或个人声誉的信息。
技术实现
安全文本检测通常采用以下技术:
自然语言处理(NLP):解析文本语义,进行情感分析。
机器学习:通过大量数据训练模型,提高检测的准确率和效率。
深度学习:使用神经网络等复杂算法来理解文本含义。
规则引擎:设置特定规则,快速匹配和处理敏感词汇或模式。
应用场景
社交媒体平台:自动监测用户发布的内容,防止不当言论传播。
电子邮件系统:识别垃圾邮件和网络诈骗,确保邮箱安全。
论坛和评论区:及时清除违规帖子,保持网络环境的清洁。
企业内部通信:防止敏感信息外泄,保证商业秘密安全。
挑战与对策
多语言支持:不同语言需要不同的处理机制,需构建多语言模型。
语境判断:相同词汇在不同上下文中含义不同,需要高级语义分析。
实时性要求:对实时互动平台的监控需要高效快速的处理能力。
误判问题:机器可能无法完全准确判断,需结合人工复审机制。
未来发展
安全文本检测将更多地利用人工智能的进步,如通过强化学习不断优化模型,以及运用更复杂的自然语言处理技术来更好地理解和处理人类语言的多样性和复杂性。
相关问题与解答
Q1: 内容安全文本检测是否会侵犯个人隐私?
A1: 内容安全文本检测主要针对公开信息,不直接关联到个人信息数据,只要合理使用并严格遵守隐私保护法规,就不会侵犯个人隐私。
Q2: 如何提高内容安全文本检测的准确性?
A2: 提高准确性的方法包括增加训练数据集的多样性和质量、采用更先进的算法、持续更新敏感词库、加强语境分析能力以及定期进行模型的评估和优化,结合人工审核机制以降低误判率。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/888293.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复