


COUNT()函数来统计重复的数据。通过将需要计数的字段放在COUNT()函数中,可以获取该字段的重复值数量。在数据库管理工作中,识别和处理重复数据是一项常见而重要的任务,特别是在使用MySQL这样的关系型数据库管理系统时,能够有效地统计和处理重复数据,对于维护数据的准确性和整洁性至关重要,本文将深入探讨在MySQL中如何利用COUNT()函数和其他相关SQL语句来检测和处理重复的数据。
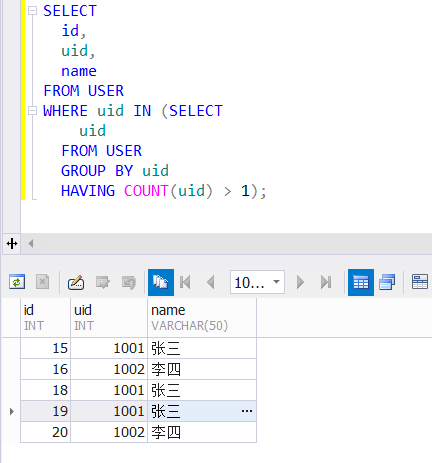

在MySQL中,COUNT()函数是用来统计行数的,特别是当需要确定某列中非NULL值的数量时,此函数可以接受一个或多个参数,并返回这些参数中非NULL值的计数,通过灵活运用COUNT(),可以有效地统计出特定列中重复值的数量。
使用 DISTINCT 关键字
当我们需要去除查询结果中的重复行时,可以使用DISTINCT关键字,若要查看表中不重复的用户名列表,可以使用如下语句:
SELECT DISTINCT username FROM test;
结合 GROUP BY 和 COUNT() 函数
为了找出具体哪些数据存在重复,以及它们的重复次数,我们可以结合使用GROUP BY和COUNT()函数,以下是一个示例查询,用于统计表中各个username的重复数量:
SELECT username, COUNT(*) as count FROM test GROUP BY username HAVING count > 1;
在这个查询中,我们首先按照username分组,然后利用COUNT(*)函数计算每组的记录数,HAVING子句过滤出那些记录数大于1的组,即存在重复的username。
删除重复数据的策略
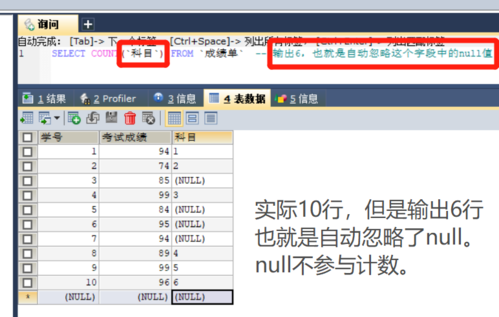
面对重复数据,常见的处理方法是保留一项(如ID最小的一条记录)并删除其他重复项,这就需要更复杂的查询和操作来确保数据的正确性,以下步骤可以帮助实现这一目标:
1、找出重复的数据及其ID:
“`sql
SELECT min(id) as min_id FROM test GROUP BY username HAVING count > 1;
“`
2、根据上一步获取的ID,删除重复的数据:
“`sql
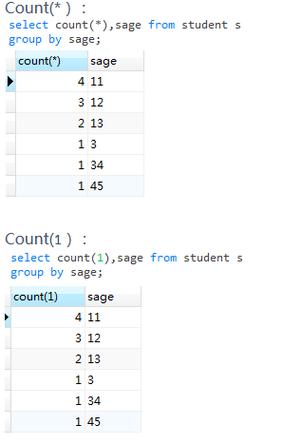
DELETE FROM test WHERE id NOT IN (SELECT min_id FROM (SELECT min(id) as min_id FROM test GROUP BY username HAVING count > 1) as temp);
“`
操作会删除除了每个username中ID最小之外的所有必要重复记录。
COUNT函数的使用不仅限于上述场景,根据具体的使用方式,还可以进行更细致的数据分析,
COUNT(expr):返回SELECT语句检索的行中expr的值不为NULL的数量。
若查询涉及多表联接,COUNT()函数可以帮助确认联接后的总行数等信息。
在MySQL中使用COUNT()函数及相关SQL技巧来处理重复数据,是一种高效且实用的方法,通过精确的查询语句设计,可以有效地识别、统计甚至删除不必要的重复记录,从而确保数据库数据的质量和性能。
FAQs
Q1: COUNT()函数能统计NULL值吗?
A1: COUNT()函数不能统计列为NULL的值,如果需要统计包含NULL值的行数,可以考虑使用COUNT(*)。
Q2: 使用GROUP BY和COUNT()统计时,能否只显示数量超过特定阈值的结果?
A2: 可以,通过在查询中加入HAVING子句设置条件,如HAVING COUNT(*) > N,就可以只显示那些计数超过N的记录。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/888233.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复