


MapReduce是一个分布式计算框架,它允许在Hadoop集群上执行大规模数据处理任务,本文将深入探讨MapReduce的基本概念、工作原理、以及常见的Join操作。
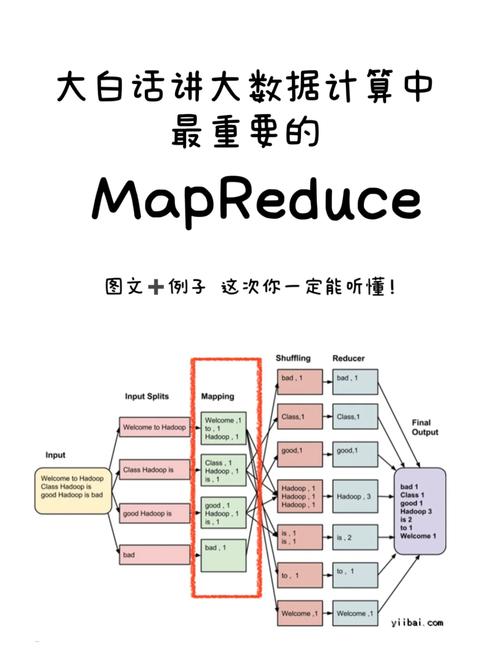

MapReduce的核心思想是将复杂的数据处理任务分解为两个阶段:Map阶段和Reduce阶段,在Map阶段,系统将输入数据拆分成多个独立的数据块,每个数据块由一个Map任务处理,生成一组中间键值对,这些中间结果随后会被shuffle和sort,以确保所有具有相同键的值被发送到同一个Reduce任务,在Reduce阶段,每个Reduce任务负责处理一个特定的键和相关的一组值,以生成最终的输出结果。
在MapReduce中,Join操作是一种基本操作,用于将来自不同数据源的数据进行连接,Join操作分为两种类型:MapJoin和ReduceJoin,MapJoin操作通常用于连接较小的数据集到较大的数据集,在这种操作中,较小的数据集会被加载到一个分布式缓存中,这样每个Map任务都能访问到这个数据集,从而实现高效的数据连接,这种方法适用于数据量不是非常大的情况,因为它需要将所有小数据集加载到内存中。
与之相对的是ReduceJoin操作,它不要求将整个数据集加载到内存中,在ReduceJoin中,Map任务的主要工作是为来自不同表或文件的键值对打上标签,以区分不同来源的记录,使用连接字段作为键,其余部分和新加的标志作为值进行输出,在Reduce端,已经完成了以连接字段作为键的分组,此时Reduce任务可以处理这些数据并输出最终的连接结果。
DistributedCache是Hadoop提供的一种机制,能够在作业执行前将指定文件分发到各个任务节点上,这对于MapReduce作业中需要访问共享文件的情况非常有用,比如在MapJoin操作中加载小数据集到所有Map任务节点,DistributedCache能够高效地缓存应用程序所需的各种文件,包括文本、档案文件、jar文件等,这种机制确保了每个作业的文件只被拷贝一次,并且为那些没有文档的slave节点缓存文档。
通过以上的分析,可以看出MapReduce框架提供了一种强大的工具来处理和分析大规模数据集,不同的Join操作和分布式缓存机制进一步扩展了MapReduce的应用范围,使其能够更有效地处理复杂的数据分析任务。
相关问答FAQs
问: MapReduce中的MapJoin和ReduceJoin有何区别?

答: MapJoin主要用于连接较小的数据集到较大的数据集,并将小数据集加载到所有Map任务的内存中进行处理,适合内存足够且小数据集不是特别大的情况,而ReduceJoin则不需要将整个小数据集加载到内存中,它通过给不同来源的记录打标签并在Reduce阶段进行数据连接,适用于更大的数据集和更复杂的连接需求。
问: 如何优化MapReduce作业的性能?
答: 优化MapReduce作业性能的方法包括合理设置数据分区以平衡负载、使用DistributedCache减少网络传输、选择合适的数据格式和序列化机制减少处理时间、以及合理配置Map和Reduce的数量来匹配集群的实际能力,避免数据倾斜也是提高性能的关键措施之一。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/887256.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复