


MapReduce处理系统及其支持的大数据平台简介

MapReduce模型是大数据领域的一种分布式计算框架,最初由Google提出并在其论文《MapReduce: Simplified Data Processing on Large Clusters》中详细描述,该模型适用于大规模数据集的处理,尤其是在非结构化数据的并行处理上表现突出,它的核心思想是将数据处理任务分解为两个主要步骤:Map和Reduce,Map阶段负责将输入数据分解成一系列的键值对,而Reduce阶段则处理这些键值对并进行聚合操作以生成最终结果。
MapReduce的关键组件包括Mapper和Reducer,Mapper负责接收原始数据,执行转换操作后输出键值对;Reducer则处理这些键值对,进行聚合并输出最终结果,这种模式使得MapReduce能够高效处理复杂的数据分析任务,并且易于实现分布式计算。
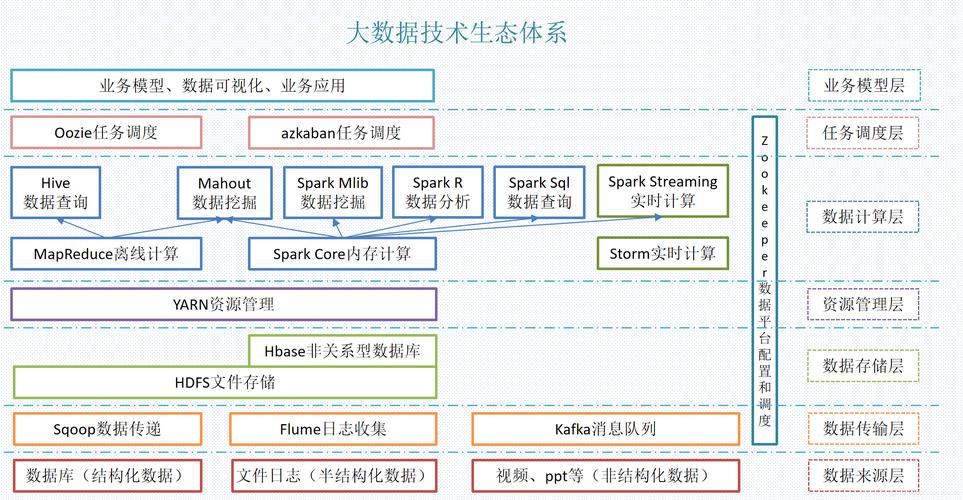
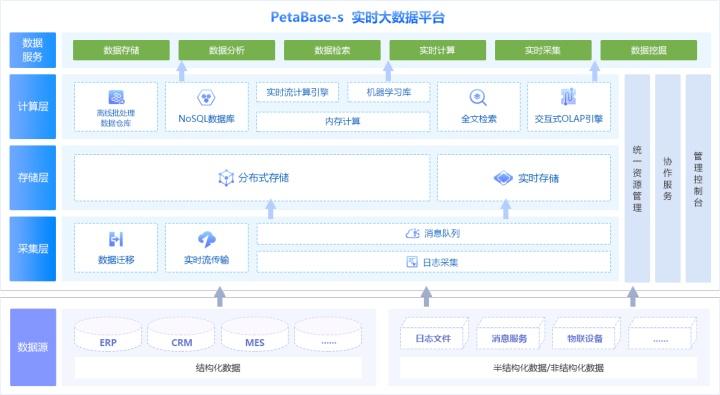
在支持MapReduce的大数据平台方面,Hadoop是一个典型的例子,作为Apache软件基金会的一个项目,Hadoop提供了一个可靠的、可伸缩的分布式计算解决方案,Hadoop生态系统包括分布式文件系统HDFS、分布式数据库HBase,以及MapReduce编程模型,这三者共同构成了面向海量数据的分布式系统的基础架构,HDFS解决了大规模数据存储的问题,而MapReduce提供了处理这些数据的能力。
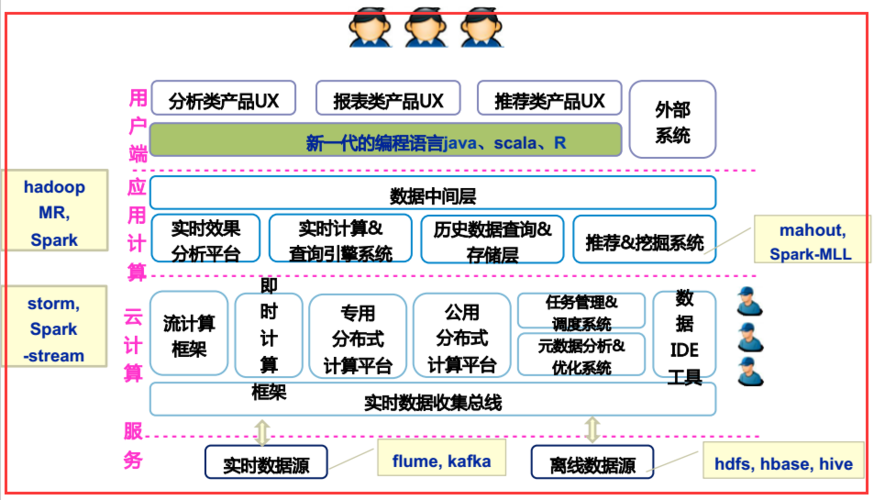
另一个值得注意的平台是基于阿里云的EMapReduce(EMR),EMR整合了Apache Hadoop和Apache Spark,允许用户方便地使用这两个生态系统中的其他工具来分析和处理数据,这标志着云计算服务提供商也开始提供兼容MapReduce模型的服务,进一步推动了大数据处理技术的普及和应用。
MapReduce模型的影响远不止于技术层面,它还代表了一种思维方式的转变,传统的数据处理方法往往无法有效应对海量数据集的挑战,MapReduce通过简化数据处理流程,使得开发者能够更容易地构建可扩展的并行处理应用,该模型的容错性和恢复机制也是其在大规模集群环境中广泛应用的重要因素。
随着大数据技术的不断发展,MapReduce模型也展现出其持久的影响力,从互联网公司到传统行业,从商业智能到科学研究,MapReduce的应用范围不断扩大,企业和研究机构利用这一模型处理和分析数据,从而获得洞察和价值,这对于数据驱动的决策过程至关重要。
归纳而言,MapReduce模型及其支持的大数据平台如Hadoop和EMR等,为处理大规模数据集提供了强大的工具和方法,这些技术和平台不仅简化了数据处理流程,还促进了大数据技术的发展和应用,对各行各业的数据分析和决策制定产生了深远的影响。
相关问答FAQs
Q1: MapReduce如何处理大规模数据?
Q1答案:MapReduce通过两个主要步骤—Map和Reduce—处理大规模数据,Map阶段将输入数据分解成键值对,而Reduce阶段则对这些键值对进行处理并生成最终结果,这一过程在多个节点上并行执行,有效提高了数据处理的效率和速度。
Q2: 为什么说MapReduce不仅是一个工具,还是一种思维方式?
Q2答案:MapReduce不仅提供了一种处理大规模数据集的技术手段,它还代表了一种新的解决问题的方法,它鼓励开发者将复杂问题分解为小的、可并行处理的任务,从而实现高效的数据处理,这种思维方式促使人们在面对海量数据挑战时,能够思考如何通过分而治之的策略来简化问题解决过程。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/886518.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复