


在分布式系统中,MySQL中间件的有效运用是确保数据高可用性、一致性和系统扩展性的关键,下文将汇总MySQL分布式中间件的最佳实践,涵盖架构设计、复制机制、多机房部署等重要方面,并提供相关案例分析及常见问题解答。
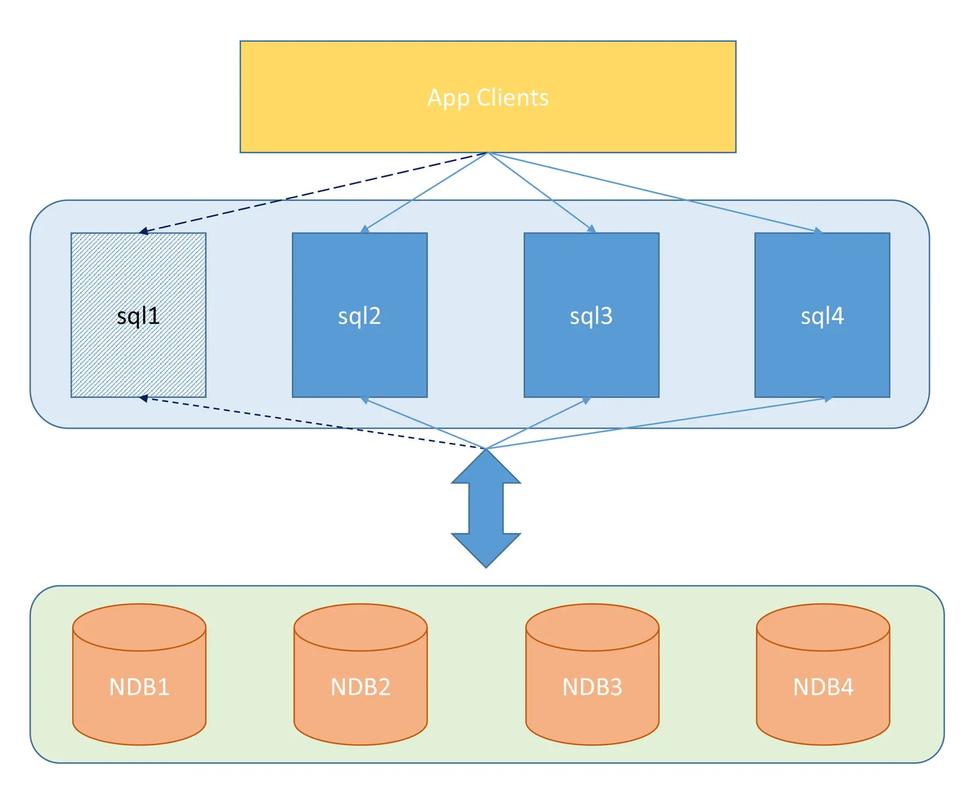

了解分布式中间件的核心场景及其设计原则至关重要,MySQL Replication是构建分布式系统的基础,其中DTLE作为一个新开源项目,旨在异构数据存储之间提供高性能和强大的复制功能,其核心场景包括数据迁移、同步和消费,尤其在多IDC架构中的数据复制技术中显示出其独特优势。
在架构设计上,最佳实践推荐采用可靠的集群机制和拓扑结构,Cobar作为阿里巴巴开源的MySQL分布式处理中间件,虽然自2013年后更新较少,但其基本架构依然为众多开发者所借鉴,一个良好的分布式中间件应支持多种数据节点,保证任一节点的故障不会影响到整个系统的运行。
关于复制机制,实践中常常需要处理数据一致性问题,MySQL分布式数据库的高可用实践指出,复制机制必须能够适应复杂的网络环境和硬件故障,确保数据的强一致性和最终一致性,携程软件的技术专家Roy所负责的双向同步DRC项目,就是对数据一致性领域的一种探索。
针对多机房部署,有效的策略包括使用主动被动模式或主动主动模式进行数据复制,这样不仅可以提升数据的可用性和灾难恢复能力,还能优化跨地域访问的响应时间,在FCon x AICon会议中提到的多家银行,都在其多机房部署中采用了此类高可用设计。
性能测试也是MySQL分布式中间件不可忽视的一个环节,据爱可生研发总监深入钻研后发现,定期的性能测试可以有效地评估中间件在处理大规模操作时的表现,从而及时调整配置策略,保持系统的最优状态。
实现MySQL分布式中间件的最佳实践涉及多个层面,从架构设计到数据复制,再到多机房部署以及性能测试,每一个环节都需要精心设计和持续优化才能构建出高效、稳定且易于扩展的分布式数据库系统。
将对一些常见问题进行解答:
FAQs
Q1: 如何选择合适的分布式中间件?
A1: 选择分布式中间件时,应考虑其是否支持所需的数据库操作、是否具备高可用与容错机制、社区活跃度、文档完善程度以及是否容易维护和升级等因素。
Q2: 分布式中间件在数据同步时遇到网络分区怎么办?
A2: 在出现网络分区时,中间件应能自动处理数据同步冲突,并保持数据的最终一致性,通常这需要通过事务日志和重试机制来实现,确保网络恢复后数据能够准确无误地同步到各个节点。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/886367.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复