


【mapreduce发展简史_SQL】

MapReduce,作为一种强大的分布式计算模型,自2004年由Google提出以来,已经极大地改变了数据处理领域的面貌,本文将探讨MapReduce的发展历程及其在现代数据处理中的重要性。
MapReduce的起源与早期发展
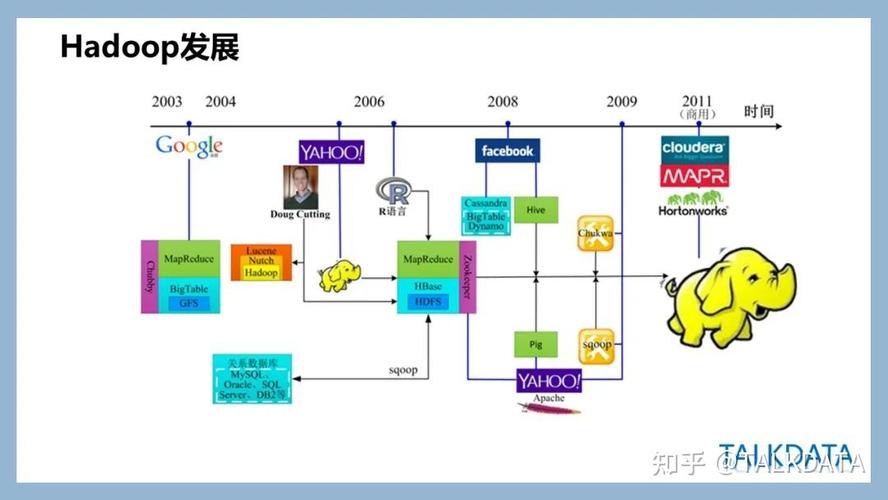
1、Google的开创性工作
2003至2004年间,Google发表了两篇开创性的论文,一篇介绍了GFS(分布式文件系统),另一篇则详述了MapReduce编程模型。
MapReduce模型最初是为了高效处理大规模网页数据而设计,它允许开发者简单地实现并行化程序,从而大幅提高数据处理速度。
2、Nutch项目和Hadoop的诞生
Nutch,一个开源的全网搜索引擎项目,最早采用了类似MapReduce的思想来处理大规模网页数据。
随后,受到Google论文的启发,Nutch团队开发出了HDFS和Hadoop,后者成为了Apache的顶级项目,并迅速在业界得到广泛应用。
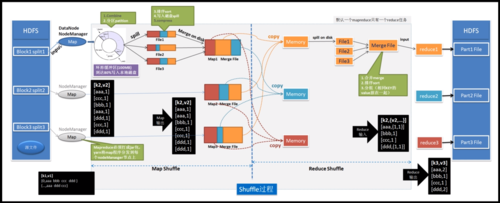
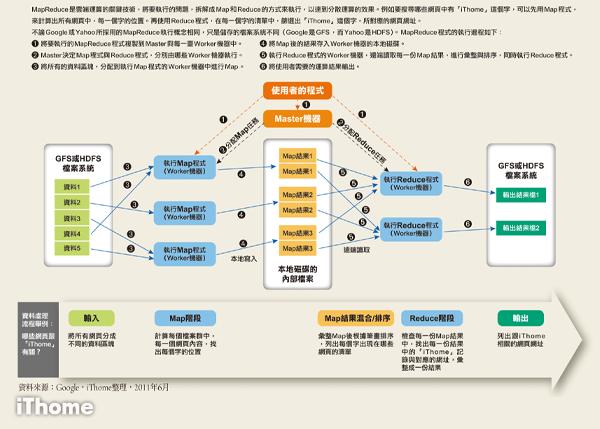
MapReduce的核心概念与优势
1、核心概念解析
MapReduce模型主要包括两个阶段:Map阶段和Reduce阶段,Map阶段对数据进行分解和处理,而Reduce阶段则负责数据的汇总和输出。
此模型通过简化分布式程序的设计,使得开发者可以容易地在大量廉价硬件上实现高性能计算。
2、技术优势显著
易于编程:用户只需实现简单的接口,即可自动获得分布式计算的能力。
扩展性强:随着数据量的增加,可以轻松扩展计算资源,无需修改应用程序代码。
MapReduce的广泛应用与影响
1、多样化的应用场景
从文本处理到复杂的数据分析,MapReduce被广泛应用于日志分析、数据挖掘和大数据分析等领域。
在生物信息学、金融分析等多个行业,MapReduce已成为处理大数据不可或缺的工具。
2、推动技术进步
MapReduce的出现促进了相关技术的发展,例如数据存储、机器学习和实时数据处理等。
它也影响了后续的计算框架设计,如Apache Spark等。
MapReduce的现代化发展与挑战
1、技术的持续创新
社区不断发展新的特性和优化算法,以适应更大规模的数据处理需求。
新技术如容器化和云服务的结合,为MapReduce带来了新的部署和运行方式。
2、面临的挑战与限制
数据倾斜和资源利用不均是MapReduce常见的问题。
随着数据量的不断扩大和计算需求的多样化,传统的MapReduce需要在效率和可扩展性方面进一步突破。
展望未来的发展
1、技术的深度融合
预计未来MapReduce将更深入地与人工智能和机器学习技术整合,以提升处理智能性和自动化水平。
云计算平台将进一步优化MapReduce的运行效率和资源管理。
2、开源生态的支持
开源社区将继续在MapReduce的发展中扮演关键角色,通过不断的贡献和优化,推动这一技术向前发展。
教育和培训将帮助更多技术人员掌握MapReduce,扩大其应用范围。
MapReduce不仅革新了数据处理的方式,也为企业提供了前所未有的计算能力,尽管面临一些技术和性能上的挑战,但随着技术的不断进步和社区的支持,MapReduce将继续在大数据领域占据重要地位。
FAQs
Q1: MapReduce适合处理什么样的数据问题?
A1: MapReduce特别适合处理大规模数据集,尤其是那些需要并行处理的场景,如日志分析、推荐系统的数据预处理、网页索引等。
Q2: MapReduce有哪些局限性?
A2: MapReduce的主要局限性包括处理效率问题、资源利用率不均以及在实时数据处理方面的不足,对于复杂的数据交互和多阶段计算任务,使用MapReduce可能会引入不必要的复杂性和开销。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/886031.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复