


在MapReduce框架中,处理大量数据的能力主要依赖于两个核心阶段:Map和Reduce,Map阶段负责数据的初步处理,将输入数据转化为键值对;而Reduce阶段则负责对Map阶段的输出结果进行汇总、排序和合并,下面将深入解析MapReduce中的Reduce合并过程,以及它在数据处理中所扮演的角色。
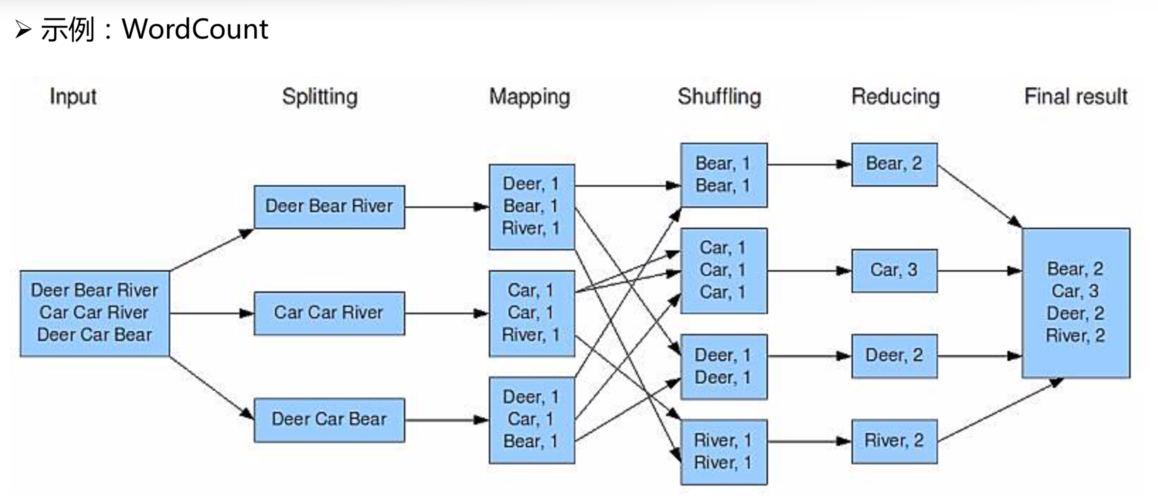

1、Map到Reduce的数据传输
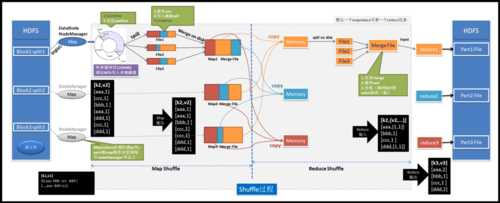
Shuffle阶段的作用:Shuffle阶段是连接Map和Reduce的桥梁,它包括数据分区、排序、缓存和合并等机制,这一阶段确保了Map阶段的输出能够高效、有序地传输到Reduce端,简言之,Shuffle使得无规则的Map输出变得有规则,便于Reduce任务的处理。
数据分区:在Shuffle阶段,Map的输出会根据一定的规则被分区,保证关联数据能够被发送到同一个Reducer上,这是通过自定义Partitioner来实现的,其目的是优化数据处理效率,确保Reduce任务能够接收到完整且有序的数据集合。
2、Reduce阶段的数据合并
逻辑清晰的Key设计:在Reduce阶段,来自Map端的键值对会根据Key进行排序和分组,这要求在设计Key的时候就要考虑到如何能够有效地将相关数据聚集在一起,以便于后续的数据合并操作。
合并策略的实施:在具体的合并操作中,通常需要根据业务逻辑来设计合并策略,在进行表连接(join)操作时,可以通过标记不同来源的数据,并在Reducer中进行相应的处理,最终实现数据的串联和合并。
3、侧路连接(Side Join)案例分析
减少网络传输开销:通过实施侧路连接,可以在Reduce端直接关联本地数据,从而避免了不必要的网络传输开销,这对于处理大数据量的场景尤为重要,可以显著提升数据处理效率。
优化数据处理流程:侧路连接不仅减少了数据传输,还优化了数据处理流程,通过在Reducer端执行连接操作,可以有效降低数据处理的复杂性,提高整体的处理速度和效率。
MapReduce框架下的Reduce合并是一个复杂但有序的过程,涉及数据的传输、排序、分组及最终的合并操作,通过精心设计的Key和合并策略,可以高效地完成复杂的数据处理任务,如大规模的数据连接操作,对于大规模数据处理,理解并正确实施Reduce合并机制,是提高数据处理效率和效果的关键。
FAQs
Q1: MapReduce中的Shuffle阶段具体是如何工作的?
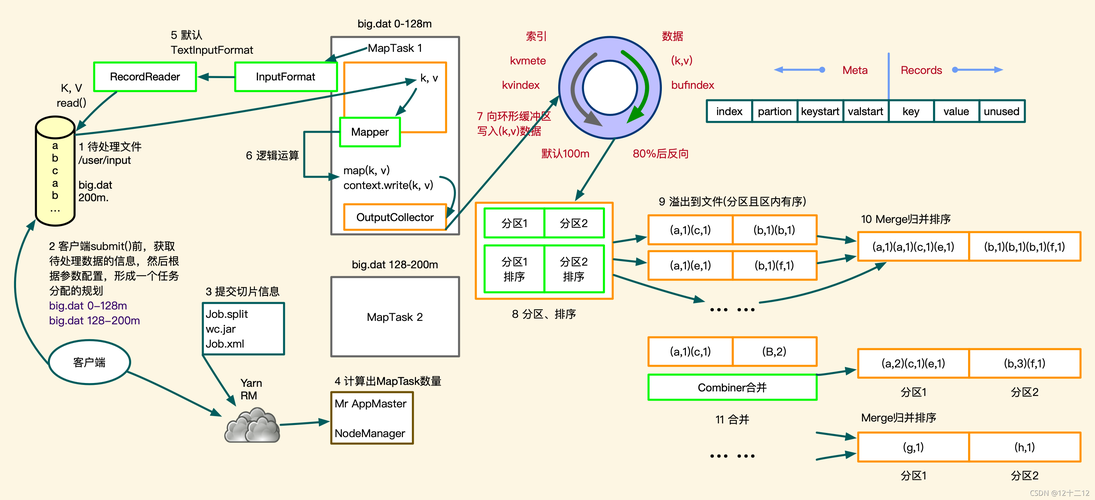
A1: Shuffle阶段是MapReduce中非常重要的一个环节,它负责将Map阶段的输出数据传输到Reduce阶段,Shuffle的工作可以分为三个步骤:Map端的输出数据会根据Key进行排序;这些数据可能被分区间,以便不同区间的数据能够被发送到合适的Reducer上;数据通过网络传输到Reducer端,在Reducer端收到数据后,会对这些数据进行合并,以准备进行最终的Reduce操作。
Q2: 在Reduce阶段,如果遇到数据倾斜问题该如何解决?
A2: 数据倾斜是指某些Key对应的数据量远远大于其他Key的情况,这会导致处理这些Key的Reducer负载过重,影响整个作业的完成时间,解决这一问题的方法有多种,一种方法是在Map阶段进行更细致的分区,尽量让数据均匀分布在不同的Reducer上,另一种方法是使用MapReduce框架提供的Skipping机制,跳过那些处理过程中已知不会影响到最终结果的Key值,也可以考虑在Reducer端使用外部存储系统来处理热点数据,减轻单个Reducer的压力。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/885990.html
 微信扫一扫
微信扫一扫