


MapReduce是处理大规模数据集的编程模型,它允许开发者只需关注于数据的映射(Map)和归约(Reduce)两个阶段,而无需关心底层的分布式处理细节,这种模型特别适合于那些需要大量计算资源进行数据分析和处理的场景,例如大数据处理,将通过一个简单的查询例子来进一步了解MapReduce的工作原理及其应用。
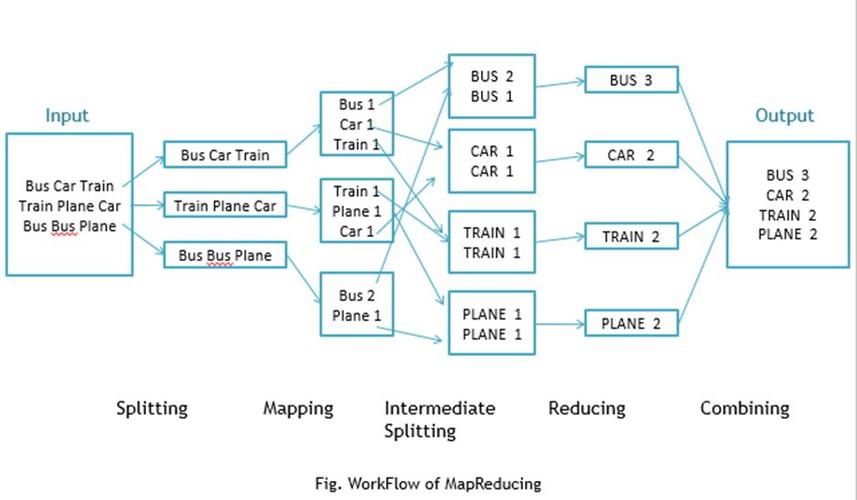

MapReduce 基本概念及流程
1、Map阶段: 在这个阶段,输入数据被分成多个数据块,每个数据块分别由一个Map任务处理,Map任务分析数据,通常以键值对的形式输出中间结果,如果任务是数单词,Map阶段的输出可能是单词及其出现次数。
2、Shuffle阶段: 这是一个中间过程,用于将Map阶段的输出传输给Reduce阶段,Shuffle主要是对数据进行排序和传输,确保Reduce阶段可以接收到所有相关数据。
3、Reduce阶段: 在这个阶段,Reduce任务将接收到的数据进行汇总或合并,输出最终结果,继续上面的例子,Reduce阶段会统计每个单词的总出现次数。
简单查询示例:WordCount
假设有一篇很大的文本数据,需要统计其中每个单词的出现频率,以下是使用MapReduce框架处理这个任务的简化步骤:
1、Map阶段: 每个Map任务读取文本数据的一个子集,并为每个单词生成一个键值对(word, 1),如果读到"apple",则输出("apple", 1)。
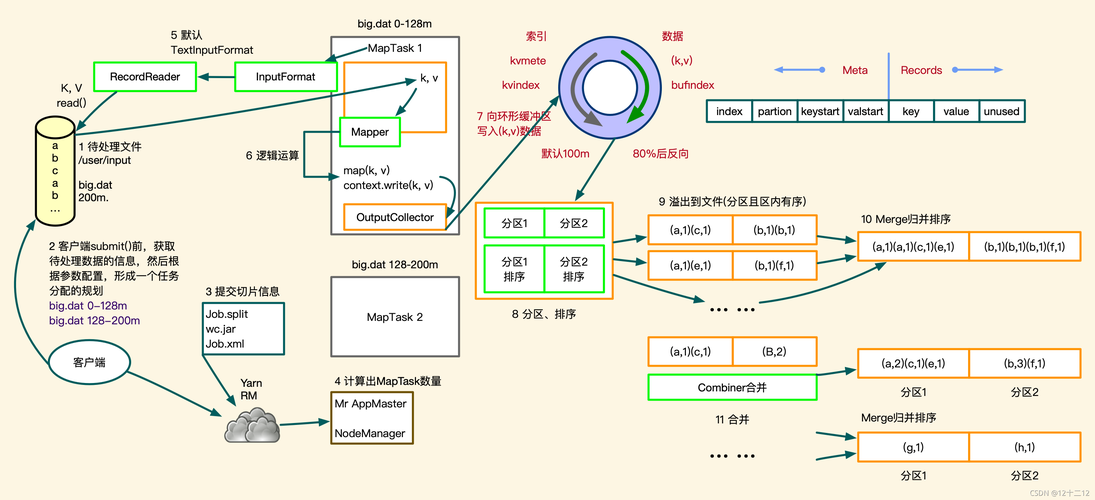
2、Shuffle阶段: 所有生成的键值对被排序并按照键(key)分组,这样,相同的单词会被归组在一起,如("apple", 1), ("apple", 1)。
3、Reduce阶段: 对于每个唯一的键(即单词),Reduce任务会累加其值,从而得到每个单词的总计数,对于"apple",Reduce输出("apple", 2)。
MapReduce 优点与缺点
优点:
易于编程: 开发者只需要实现Map和Reduce函数,即可完成复杂的数据处理任务。
良好的扩展性: 通过增加更多的机器,可以轻松扩展系统的处理能力。
高容错性: 设计初衷即为在廉价硬件上运行,自动故障恢复机制确保任务稳定执行。

缺点:
实时处理不足: 不适合需要快速响应的实时数据处理。
资源消耗: 在处理小量数据时,MapReduce的开销可能会超过其性能优势。
相关FAQs
1. MapReduce适用于哪些场景?
MapReduce最适合处理大规模离线数据分析任务,如日志分析、推荐系统的基础数据处理等,特别是当数据量大到单台机器难以处理时,MapReduce的分布式处理能力显得尤为重要。
2. MapReduce如何处理失败的任务?
MapReduce框架设计了高容错机制,当某个任务失败时,框架会自动重新分配任务到其他节点重试,这个过程对用户透明,保证了数据处理的稳定性和可靠性。
通过上述解析,可以看到MapReduce作为处理海量数据的强大工具,不仅简化了编程复杂性,还提供了强大的扩展性和容错性,尽管存在一些局限性,如不适用于实时数据处理,但MapReduce在大数据处理领域的地位依旧不可动摇,希望本文能帮助读者更好地理解MapReduce的基本概念、工作流程及其优缺点,以及如何利用这一模型解决实际问题。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/885144.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复