


在MapReduce框架中,心跳机制(Heartbeat Mechanism)扮演着至关重要的角色,这一机制不仅涉及到任务分配和监控,还关乎整体系统的健康和稳定性,本文将深入探讨MapReduce中的心跳机制,包括其工作原理、目的、以及如何通过心跳保持系统的高效运行。

心跳机制的基本原理
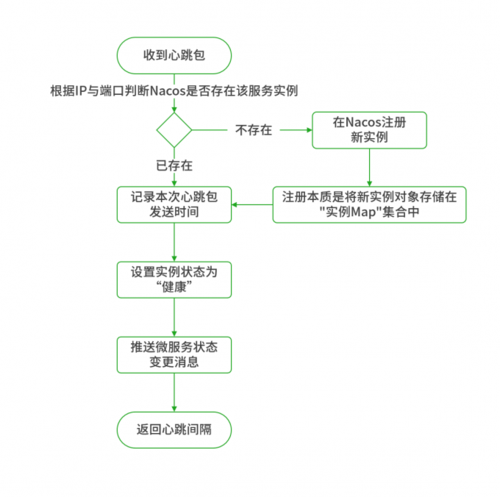
心跳机制是一种周期性的信号交换过程,用于在MapReduce的两个主要组件—JobTracker和TaskTracker之间传递信息,在这一过程中,TaskTracker定期向JobTracker发送心跳信息,报告其状态,包括资源使用情况、任务运行状况等。
这种机制确保了JobTracker能够实时获取各个节点的最新信息,从而有效地管理和调配集群资源,如果某个TaskTracker因故障停止响应,JobTracker将通过缺失心跳信号迅速检测到这一问题,并可采取相应措施,如重新分配任务到其他节点。
心跳信息的发送与接收
在MapReduce框架中,心跳信息的发送通常是由TaskTracker节点发起的,这些节点按照预设的时间间隔,自动向JobTracker发送包含关键信息的心跳包,这个时间间隔可以根据实际需求进行调整,但通常比较短,以确保信息的实时性。
JobTracker收到心跳信息后,会对其进行解析,更新其维护的节点状态列表,它会回复一个应答信号,确认接收到心跳信息,这一应答有时候还包括对TaskTracker的进一步指令,如新的任务分配或配置更新。
心跳机制的关键功能
1. 任务分配
心跳机制使得JobTracker能够根据各节点的负载和资源状况动态分配任务,通过分析心跳信息,JobTracker可以识别出哪些节点较为空闲,从而向这些节点推送新的任务,优化整个系统的负载分布。
2. 状态监控
心跳信息为JobTracker提供了实时的数据支持,使其能够监控整个集群的运行状态,这包括节点的健康状况、资源使用率、任务执行进度等,这些数据对于预防和快速响应系统故障至关重要。
3. 故障恢复
在发生节点故障的情况下,心跳机制允许系统快速做出反应,一旦JobTracker检测到来自某节点的心跳信号中断,它可以标记该节点为不可用,并重新分配其上的任务到其他健康节点上,这样最大程度减少了单点故障对整个系统的影响。
心跳机制的高级应用
除了基本的任务分配和状态监控,心跳机制还可以被扩展应用于更多高级功能:
自动恢复:在处理大规模数据时,节点可能会因各种原因暂时失去响应,心跳机制可以通过暂时的错误自动恢复流程,减少人工干预的需要。
资源优化:通过长期收集和分析心跳数据,管理员可以优化整个集群的配置,提高资源使用效率和计算性能。
心跳机制是MapReduce框架中一项关键技术,它通过简单的周期性信号交换,实现了复杂的集群管理和任务调度功能,通过不断优化这一机制,可以进一步提升Hadoop集群的稳定性和效率,满足日益增长的数据处理需求。
FAQs
Q1: 心跳机制是否可以自定义时间间隔?
A1: 是的,心跳信息发送的时间间隔是可以自定义的,管理员可以根据集群的实际运行情况和性能需求调整心跳频率,以平衡通信负载和信息实时性的需求。
Q2: 如果JobTracker未能接收到心跳会发生什么?
A2: 如果JobTracker未能在预期时间内接收到来自TaskTracker的心跳信息,它会判定该TaskTracker出现问题,并触发故障恢复流程,包括任务重新分配和错误报告,这确保了系统的高可用性和故障容错能力。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/884632.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复