


MapReduce是大数据处理的基石,本文将深入探讨MapReduce网络技术的各个方面,包括其基础概念、核心组件、优化技术及应用实例,具体分析如下:

1、MapReduce的基础和历史背景
起源与发展:MapReduce由谷歌在2003年提出,旨在简化大数据集的处理,谷歌在SOSP和OSDI上发表的相关论文奠定了其在大数据及云计算领域的重要地位。
基本概念:作为一种编程模型,MapReduce允许开发者编写代码处理大规模数据集,尤其是非结构化数据,它通过两个主要的函数—Map和Reduce—来组织计算任务。
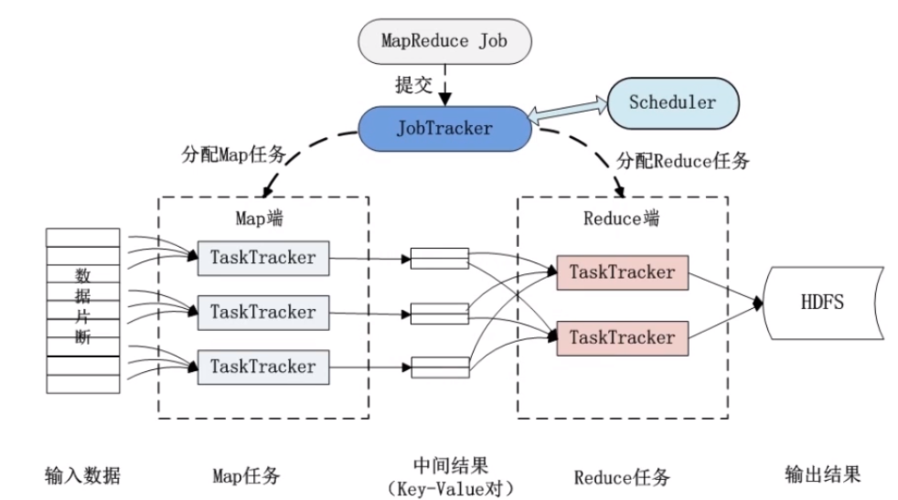
2、MapReduce的核心组件与工作流程
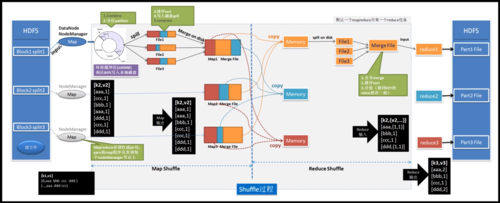
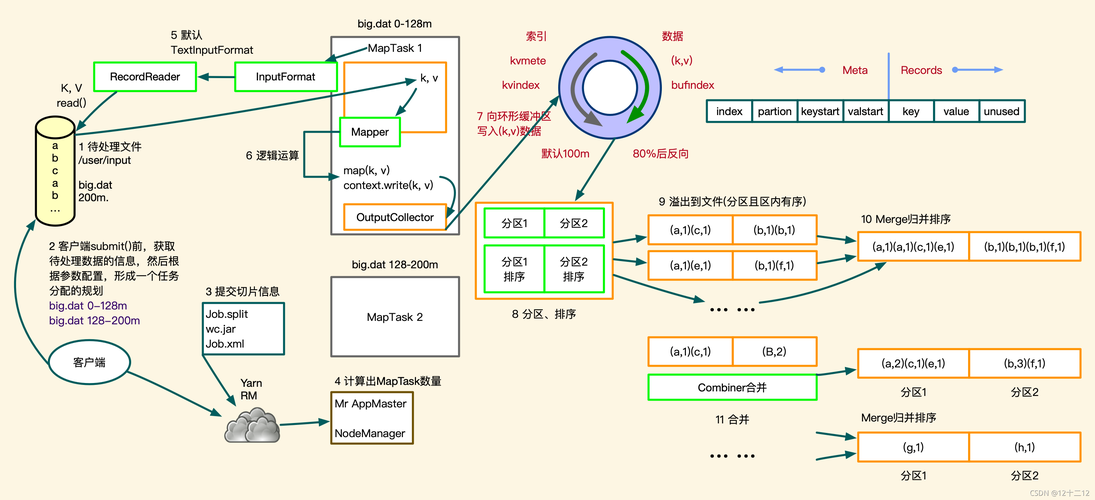
Mapper:在Map阶段,Mapper组件负责接收原始数据,通过用户定义的Map函数转换成键值对输出,每个Mapper处理的数据块独立于其他数据块,使得数据处理可以高度并行化。
Reducer:Reduce阶段则通过用户定义的Reduce函数,将具有相同键的所有值集合起来,进行处理并输出最终结果,这个阶段通常涉及数据的汇总或聚合操作。
Shuffle:在Map和Reduce阶段之间,必须进行数据分发,即Shuffle阶段,这个阶段协调各个Mapper和Reducer之间的数据流,确保每个Reducer都能接收到正确的数据片段。
3、MapReduce的优化技术
数据局部性优化:为了提升作业执行效率,MapReduce通过尽量将计算任务发送到存储有相应数据分片的节点上来减少网络传输的延迟和带宽消耗。
容错机制:作为一个稳健的分布式系统,MapReduce能够在节点失败时重新调度任务,保证数据处理的正确性和完整性。
4、MapReduce在不同领域的应用实例
信息检索和网络搜索:作为谷歌提出的技术,MapReduce最初就是用于支持其庞大的网络搜索索引构建。
日志处理和数据分析:在大型网站和互联网服务中,MapReduce被广泛应用于日志文件的分析,从而帮助理解用户行为和优化服务。
科学研究:在生物学、天文学等科学领域,MapReduce常用于处理和分析大量的实验数据和观测数据。
在了解以上内容后,以下还有几点需要注意:
数据预处理的重要性,输入数据的格式和清洗程度直接影响到MapReduce作业的效率。
考虑数据的倾斜问题,即某些键的值过多可能导致个别Reducer负载过重,需要适当的调优策略。
确保网络的稳定性和带宽,因为数据传输在分布式计算中仍然是性能瓶颈之一。
结合上述信息,MapReduce不仅是一种强大的编程模型,也是实现大数据处理的关键技术,它的设计哲学及其优化技术使其能够高效地处理和分析海量数据,尽管面对现代更为复杂的数据处理需求,人们可能会选择更现代的框架如Apache Spark,对于初入此领域的用户来说,理解MapReduce的概念与应用仍然是非常重要的基础。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/884095.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复