


【mapreduce 分位平响_MapReduce】


在当今数据驱动的时代,处理大规模数据集已成为企业和科研机构面临的一大挑战,MapReduce模型,作为一种强大的分布式计算框架,提供了一种解决方案,能够有效处理海量数据,本文将深入探讨MapReduce的核心概念、工作流程以及其在实际场景中的应用,帮助读者全面理解这一技术。
MapReduce基础概念
MapReduce是由Google提出的一种编程模型,旨在简化大数据集的处理,它通过两个主要的函数,即Map和Reduce,来处理数据,Map函数负责将输入数据转换为键值对,而Reduce函数则负责根据键来归纳和整理数据,这种模型非常适合在大规模的集群上并行处理大量数据。
工作流程
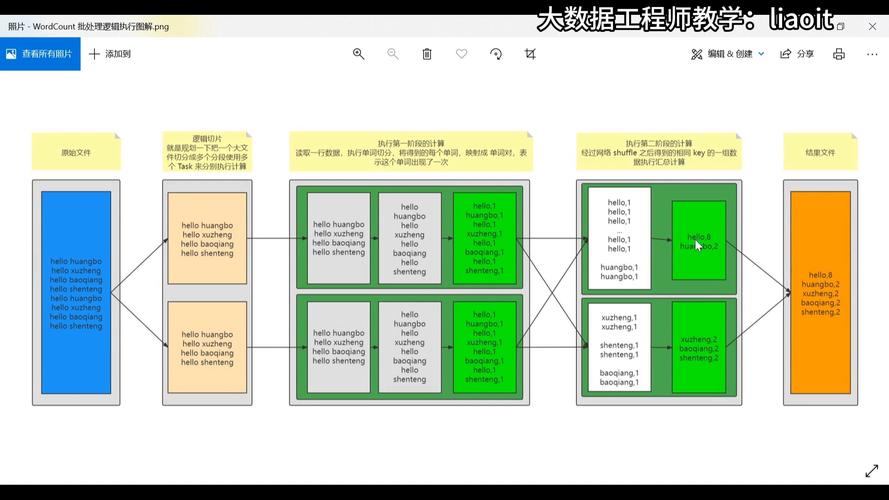
1、数据分片(Data Splitting):在MapReduce作业开始之前,输入数据会被分割成多个片段,每个片段由一个Map任务处理,分片逻辑通常是基于文件大小,Hadoop默认的blockSize是128M,如果文件使用Gzip或Snappy等不支持切分的算法压缩,则不管文件多大都只会有一个分片。
2、Map阶段:Map任务开始执行时,会细读分片中的数据记录,将每条记录转换成键值对,按照用户定义的Map函数逻辑处理这些键值对,生成中间结果。
3、Shuffle和Sort阶段:Map任务的输出需要经过Shuffle和Sort阶段,以便将具有相同键的值聚集在一起,并分发到合适的Reduce任务,这个阶段是优化整个MapReduce作业性能的关键部分。
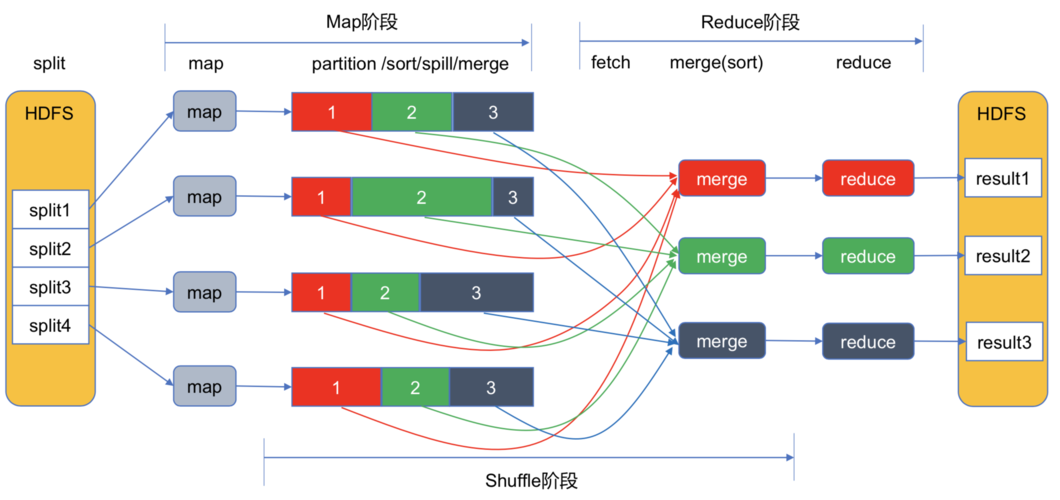
4、Reduce阶段:在Reduce阶段,每个Reduce任务会接收到来自不同Map任务的所有具有相同键的键值对,Reduce任务会根据用户定义的逻辑对这些值进行归约操作,最终输出结果。
分区(Partitioning)
在MapReduce中,分区是一个重要概念,它决定了哪些键值对应该发送到哪个Reduce任务,通过合理配置分区,可以优化数据处理过程,将同类数据发送到同一个Reduce任务进行处理,从而实现高效的数据处理和统计。
实际应用案例
日志分析:网站服务器每天都会生成大量的日志文件,使用MapReduce可以轻松处理这些日志数据,如统计页面访问量、用户访问行为等。
数据挖掘:对于结构化数据集,MapReduce可以用来执行复杂的数据挖掘算法,从而发现数据中的模式和趋势。
机器学习:许多机器学习算法需要进行大规模的数据处理,MapReduce提供了一种有效的方式来并行处理训练数据,加速模型的训练过程。
FAQs
Q1: MapReduce如何处理数据倾斜问题?
A1: 数据倾斜是指某个或某些键的值远远多于其他键,导致处理时间延长,解决这一问题的策略包括预先对数据进行采样分析,调整分区策略,或者在Map阶段使用更复杂的数据结构如哈希函数来分散数据。
Q2: 如何优化MapReduce作业的性能?
A2: 优化措施包括合理设置数据分片大小,选择合适的分区策略以平衡Reduce任务的负载,优化数据序列化方式减少数据传输量,以及适当增加Reduce任务的数量以提高并行处理能力。
通过上述讨论,我们可以看到MapReduce作为一个强大的分布式计算框架,不仅适用于大数据处理,也极大地促进了现代数据处理技术的发展,了解其基本工作原理与应用实例,有助于我们更好地利用这一框架解决实际问题。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/884010.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复