


在当今的社交网络平台中,推荐好友功能是一个增强用户互动和提升用户体验的重要特性,通过MapReduce模型实现的推荐好友算法,不仅高效处理大规模数据,还能在复杂网络中为用户发现潜在的社交联系,下面将深入探讨这一技术的应用背景、实现方式及其在现实世界的具体影响。
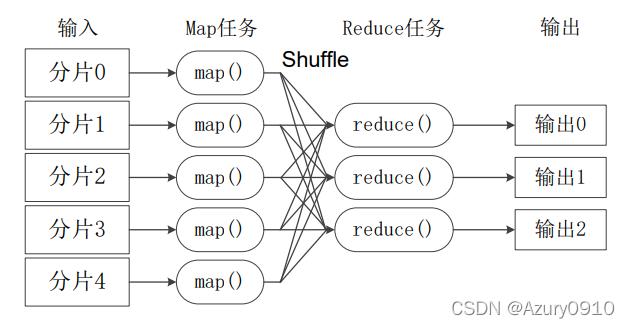

MapReduce模型由Google提出,旨在处理和生成大规模数据集,该模型特别适用于需要处理海量数据的场景,如社交网络的好友推荐系统,在这样一个系统中,好友推荐的算法通常基于用户间的共同好友数量进行推荐,这种方法不仅简单有效,而且易于通过MapReduce框架实现。
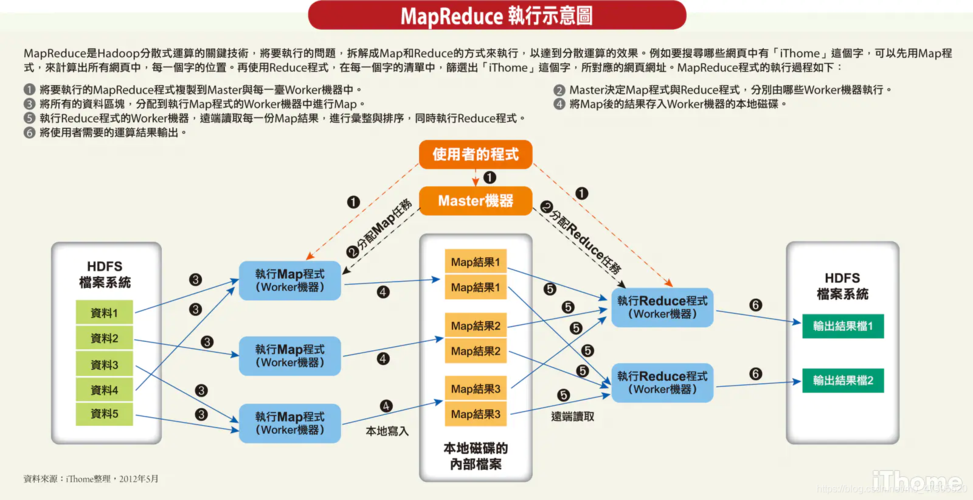
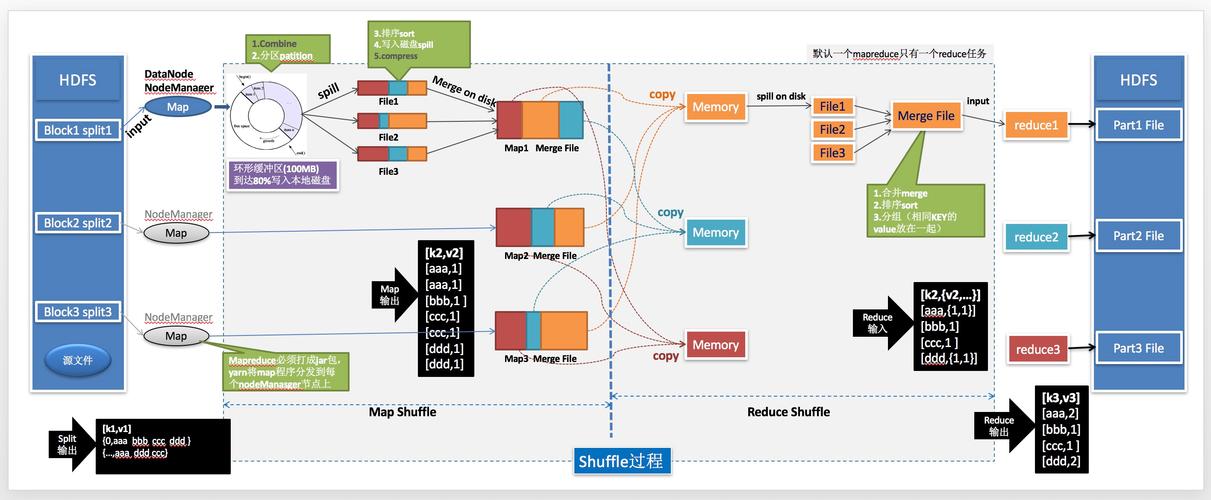
具体到实现方法,可以通过搭建Hadoop和Zookeeper集群,并配置HDFS和MapReduce环境来进行,开发过程中,首先需要准备Java项目,并利用工具类随机生成好友关系作为测试数据,接下来是编写具体的Map和Reduce逻辑,最后通过Job类提交任务进行处理,整个过程涉及数据的分布式存储和并行计算,显著提高了数据处理的效率和扩展性。
一个典型的应用场景是社交网络中的“可能认识的人”推荐功能,这种功能通常根据用户之间的共同好友数量来计算推荐值,并进行排序显示给用户,通过MapReduce实现时,Mapper阶段可以计算每个用户的共同好友数,而Reducer阶段则可以对这些数据进行汇总和排序,用户可以接收到一份根据共同好友数量排序的潜在好友列表。
使用MapReduce模型实现推荐好友的算法具有多方面的优势,它能够处理的数据量远超传统数据库或单机处理能力,适合当前社交网络用户规模庞大的特点,该模型的分布式计算特性使得计算资源可以得到更有效的利用,从而加快数据处理速度,由于算法的运行分布在多个节点上,系统的容错性和稳定性也得到了增强。
实现此类系统也面临一些挑战和限制,数据的安全性和隐私保护是构建推荐系统时必须考虑的问题,如何在不泄露用户个人信息的前提下提供准确的好友推荐,是技术实施中的一大难题,随着用户需求的多样化,仅依靠共同好友数量可能无法满足所有用户的推荐需求,因此算法可能需要进一步集成其他因素,如兴趣、活动等个性化信息。
针对上述内容,以下是一些考虑因素:
1、数据安全和隐私
如何确保在计算和推荐过程中不泄露用户的私人信息?
是否有必要引入匿名化处理或加密技术以保护数据?
2、算法的扩展与优化
除了共同好友数量,还可以考虑哪些因素来丰富推荐算法?
如何平衡算法复杂度和计算资源的消耗?
MapReduce在推荐好友的应用场景中展示了其处理大规模数据集的强大能力,为社交网络用户提供了便捷和个性化的服务,通过合理的设计和优化,这种技术不仅能提高用户满意度,还能增强平台的社交连接功能。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/883673.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复