


配置MapReduce Job日志
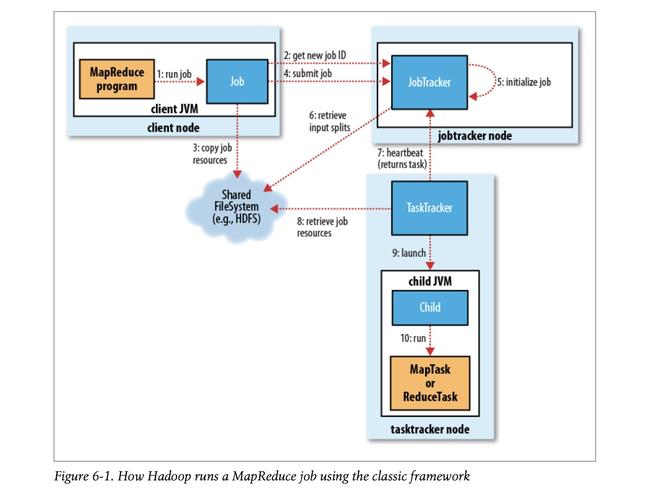

在Hadoop生态系统中,MapReduce是处理和生成大数据集的核心组件,对于任务调试、监控和性能分析而言,MapReduce作业的日志扮演着至关重要的角色,默认情况下,并没有开启MapReduce作业的日志功能,需要通过一系列的配置和操作来启用。
日志位置与HistoryServer启动
要查看MapReduce的日志信息,首先需要启动HistoryServer,HistoryServer是Hadoop中的一个服务,用于查看已经完成的MapReduce作业的日志,在默认情况下,该服务是未启动的,需要手动启动,并确保相关的配置文件已经恰当地进行了设置。
配置JobHistory
JobHistory负责记录每次MapReduce作业的运行日志,这些日志信息保存在HDFS目录中,要在HDFS中查看这些日志,需要在mapredsite.xml文件中进行配置,并手动启动JobHistory服务,配置过程中需要注意指定的参数,以确保日志信息的完整性和可访问性。
配置要点
在mapredsite.xml中的配置通常包括以下几个方面:
1、指定JobHistory的存储地址:配置HDFS上的位置,这决定了日志文件存放的路径。
2、设置日志级别:根据需要设置日志的详细程度,如INFO、WARN、ERROR等。
3、启用或禁用其他日志相关的特性:例如压缩历史日志以节省空间,或者设置日志保存的时间周期。
通过上述的配置,可以有效地控制MapReduce作业日志的记录和访问方式,为作业调试和性能分析提供了便利。
配置MapReduce Job基线
确定MapReduce Job的基线是调优工作中的基础,任何调优效果的检验都是通过与基线数据的对比来完成的,基线的确定遵循一定的原则和方法,旨在充分利用集群资源,同时保障作业的稳定性和效率。
基线确定原则
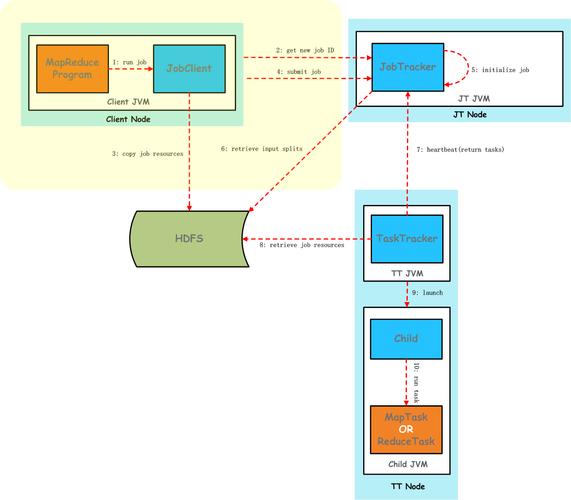
Job基线的确定遵循以下三个主要原则:
1、集群资源最大化利用:配置时应考虑如何充分利用集群的资源,包括计算能力、内存和存储空间。
2、Reduce阶段的配置:在MapReduce作业中,Reduce阶段通常是性能瓶颈所在,合理的配置可以显著提升作业执行效率。
3、稳定性与效率的平衡:基线配置应当确保作业不仅效率高,还要运行稳定,避免因过度优化导致的系统崩溃或数据丢失。
基线配置实践
在实际操作中,配置MapReduce Job基线可能涉及以下几个具体步骤:
1、资源分配:根据作业的需求和集群的实际情况,合理分配Map和Reduce任务所需的资源。
2、参数调整:调整MapReduce框架的运行时参数,如内存使用量、JVM设置等,以达到最优的作业执行效率。
3、测试与评估:经过初步配置后,通过实际运行作业并监控其性能,评估配置的效果是否符合预期。
配置MapReduce作业日志及基线是一项重要的任务,它不仅有助于问题的诊断和性能的优化,还是维护整个Hadoop生态系统稳定运行的关键,通过恰当的配置和不断的调优,可以显著提高大数据处理的效率和质量。
FAQs
为什么MapReduce作业日志有时不可见?
MapReduce作业日志可能不可见的主要原因有两点,第一是没有启动HistoryServer服务,该服务负责将作业日志从HDFS读取并展示给用户,若服务未启动,则无法查看日志,第二是配置问题,如果mapredsite.xml中的相关配置不正确或未启用JobHistory,也会导致日志记录失败或无法查看。
如何优化MapReduce Job的性能?
优化MapReduce Job性能可以从以下几个方面入手:确保合理的资源配置,比如为Map和Reduce任务分配适量的内存和CPU;调整合适的JVM参数,比如增大堆内存限制;使用合适的数据输入格式和压缩方式减少数据传输量;持续监控作业运行情况,根据实际表现调整配置参数。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/883133.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复