

MapReduce 实现平均分计算
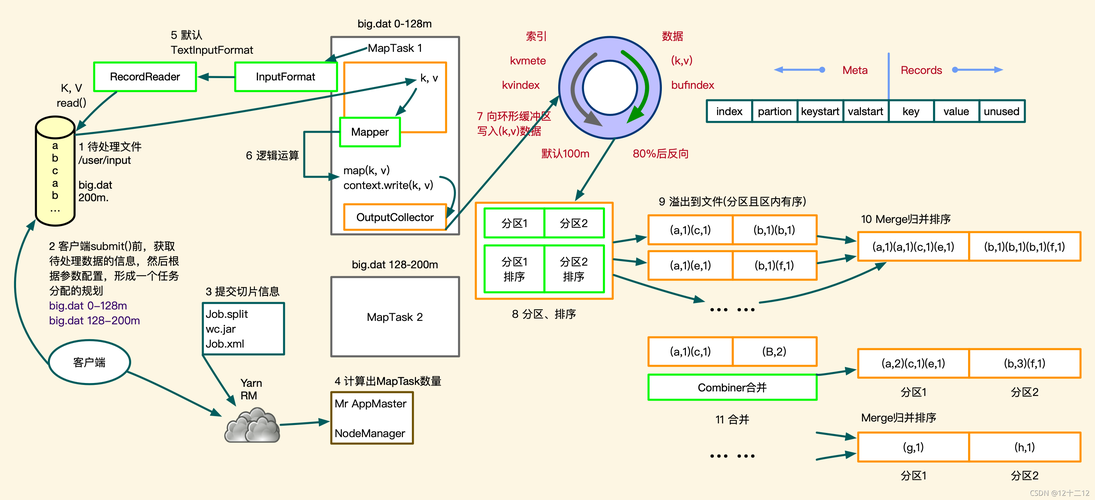

在大数据时代,处理海量数据成为了一个普遍的需求,MapReduce 作为一种编程模型,被广泛应用于分布式数据处理中,其核心思想是将大规模数据处理任务分解为多个小任务并行执行,然后再将结果汇总,本文将介绍如何使用 MapReduce 框架来实现平均分的计算。
MapReduce 简介
MapReduce 由 Google 提出,用于解决大规模数据集(大于1TB)的并行运算问题,它包含两个阶段:Map 和 Reduce。
Map 阶段:对输入数据进行分割,形成多个数据块,每个数据块分配给一个 Map 任务,Map 任务处理数据块后产生中间键值对 (keyvalue pair)。
Reduce 阶段:根据中间键值对的 key 进行排序和分组,将具有相同 key 的值集合传递给一个 Reduce 任务,Reduce 任务处理这些值并输出最终结果。
实现平均分的 MapReduce 过程
Step 1: Map 阶段
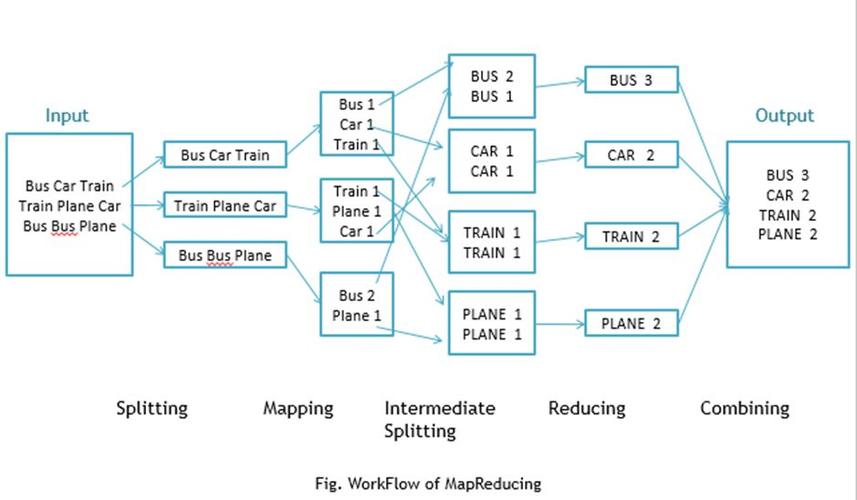
在 Map 阶段,我们的目标是读取学生的分数数据,并为每个学生生成一个键值对,其中键是学生的ID,值是该学生的分数。
输入样例:
Student ID, Score 001, 85 002, 90 003, 78 ...
Map 函数伪代码:
def map():
for each line in input_data:
split line into student_id and score
emit(student_id, score) Step 2: Shuffle and Sort
在这个阶段,框架会自动将所有 Map 任务的输出按键进行排序,并将具有相同键的值聚集在一起,准备传给 Reduce 阶段。
输出示例:
001 [85] 002 [90] 003 [78] ...
Step 3: Reduce 阶段
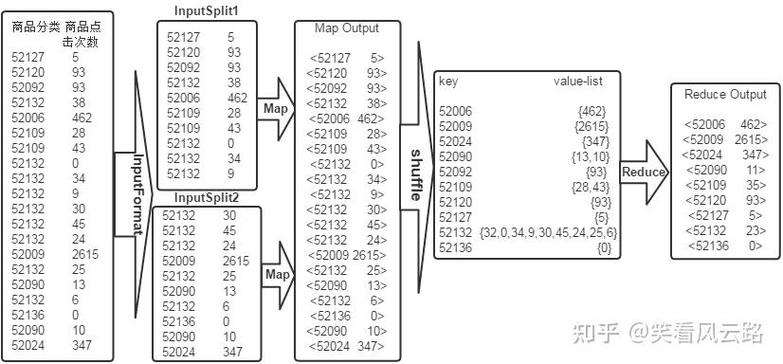
Reduce 阶段的任务是接收来自 Map 阶段的输出,并计算每个学生的平均分,由于我们只关心每个学生的一个分数,因此可以直接计算平均值。
Reduce 函数伪代码:
def reduce(student_id, scores):
average = sum(scores) / len(scores)
emit(student_id, average) Step 4: 输出结果
Reduce 阶段的输出即为每个学生的平均分。
输出示例:
001 85.0 002 90.0 003 78.0 ...
优化与考虑
数据倾斜:如果某些学生有多门课程的分数需要平均,那么在 Reduce 阶段就需要处理这个学生的所有分数来计算平均分,这可能导致数据倾斜问题,即某个 Reduce 任务处理的数据远远多于其他任务,从而影响整体性能。
容错性:MapReduce 框架通常具备容错机制,能够处理节点失败的情况,如果在 Map 或 Reduce 过程中有节点失败,框架会自动重新分配任务到其他节点执行。
扩展性:MapReduce 的设计允许轻松添加更多的计算资源来处理更大的数据集,只需增加更多的 Map 和 Reduce 节点即可。
相关问答 FAQs
Q1: MapReduce 是否适用于所有类型的大数据问题?
A1: 不是,MapReduce 最适合于数据密集型的批量处理任务,特别是那些可以分解为独立子任务的问题,对于需要实时交互或者多次迭代的算法,MapReduce 可能不是最佳选择。
Q2: 如何优化 MapReduce 作业的性能?
A2: 优化 MapReduce 作业性能的方法包括:合理设置 Map 和 Reduce 的数量以平衡负载;使用压缩技术减少数据传输量;优化数据存储格式以加快读写速度;以及合理设计键值对以减少网络传输等。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/882283.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复