


简介

MapReduce是一个编程模型,用于处理和生成大数据集,它包含两个主要阶段:映射(Map)和归约(Reduce),在Map阶段,数据被分成多个小块,每块由一个Map任务处理;而在Reduce阶段,所有Map任务的输出被整合以得到最终结果。
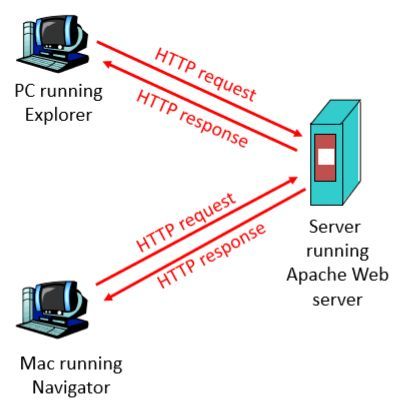
HTTP(超文本传输协议)是互联网上应用最为广泛的协议之一,它定义了客户端和服务器之间交换数据的规则和标准,在MapReduce框架中,可以通过HTTP协议来传输数据,实现分布式计算任务与外界的数据交互。
MapReduce与HTTP的结合
在大数据环境中,MapReduce作业可能需要从Web APIs或在线资源获取数据,或者将结果发送到Web服务,这时,HTTP协议成为数据传输的桥梁,Hadoop MapReduce可以利用HTTP来实现数据的输入和输出。
HTTP作为MapReduce的输入源
读取数据:MapReduce作业可以通过HTTP GET请求从Web服务器下载数据文件。
数据格式:下载的数据通常是CSV、JSON或XML格式,这些格式易于解析和处理。
认证:如果数据源需要认证,可以使用HTTP basic auth或OAuth等机制。
HTTP作为MapReduce的输出目标
发送数据:处理完成后,Reduce任务可以将结果通过HTTP POST或PUT请求发送到Web服务器。
REST APIs:通常使用RESTful APIs来接收MapReduce的输出数据。
数据格式:输出数据通常为JSON或XML格式,方便其他服务或应用程序使用。
安全性考虑
加密通信:确保使用HTTPS协议来保护数据的安全。
数据完整性:验证接收到的数据的完整性,防止在传输过程中被篡改。
优势与挑战
优势
灵活性:能够轻松地从多种Web源获取数据,或将数据发送到不同的目的地。
实时性:可以实时处理来自Web的数据流。
互操作性:促进了不同系统之间的数据交换和集成。
挑战
网络延迟:依赖于网络连接的质量,可能会影响作业的执行效率。
数据一致性:需要确保从Web源获得的数据是最新的且一致的。
错误处理:必须妥善处理HTTP请求的错误和异常情况。
实践建议
缓存机制:对于频繁访问的Web资源,可以考虑实施缓存机制减少等待时间。
并发控制:合理设置并发请求的数量,避免对Web服务造成过大压力。
错误重试:实现错误重试逻辑,以应对暂时的网络问题或服务器错误。
相关技术
Apache Nutch:一个开源的网络搜索引擎,它使用了MapReduce来处理网页内容。
Hadoop:一个广泛使用的MapReduce框架,支持通过HTTP进行数据的输入和输出。
FAQs
Q1: MapReduce作业通过HTTP获取数据时,如何处理大型文件?
A1: 当通过HTTP获取大型文件时,可以采用分块下载的方法,MapReduce作业可以先下载文件的一个小块,然后处理这一部分数据,接着再下载下一块,依此类推,这样可以有效减少内存消耗,并允许作业在数据处理的同时逐步下载文件。
Q2: 如果HTTP服务不稳定,MapReduce作业怎样保证数据的完整性?
A2: 为了保证数据的完整性,可以在MapReduce作业中实现校验机制,例如通过计算数据的哈希值并与服务器提供的哈希值进行对比,可以设置重试机制,当请求失败或超时时自动重新尝试,直到成功或达到最大重试次数。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/882279.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复