


MapReduce关联算法和关联预测算法是处理大规模数据集的重要工具,特别是在数据挖掘和机器学习领域,这些算法通过发现数据集中项之间的有意义关系,帮助人们理解数据的内在结构,从而做出更为精准的预测和决策,下面将深入探讨MapReduce框架下的关联规则挖掘算法:
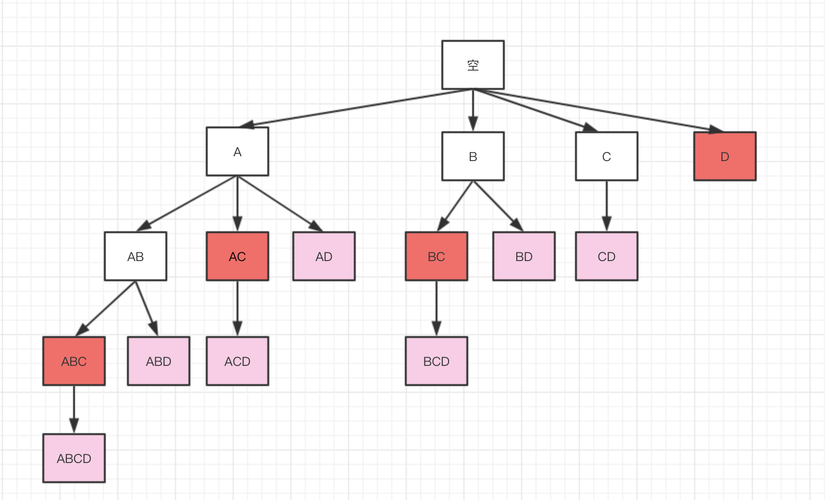

1、关联规则挖掘基本概念
定义与目的:关联规则挖掘旨在发现大数据集中变量间的有趣关系,这些关系通常以“如果X,则Y”的形式表达,算法的目标是找到数据中频繁出现的项集,并基于这些项集生成关联规则。
应用场景:在商业分析和市场篮分析中应用广泛,如通过分析顾客购买行为来优化商品放置、促销策略等。
2、Apriori算法基础及特性
算法原理:Apriori算法是一种基于迭代方法产生频繁项集的算法,它通过多次扫描数据库并利用先验知识(较小的频繁项集生成较大的候选项集)逐步构建出所有频繁项集。
关键步骤:主要包括产生候选集、计算支持度和筛选频繁项集,每次迭代中,算法都会根据最小支持度阈值筛选出频繁项集,直至无法产生新的频繁项集为止。
3、MapReduce模型与Apriori算法结合

分布式计算优势:MapReduce为处理大规模数据集设计了一种编程模型,可以在集群中并行处理数据,这使得Apriori算法能够高效处理大规模数据集,尤其是在多节点环境中。
实现方式:通过将Apriori算法的输入和输出转换为MapReduce所需的〈key, value〉模型,并在Hadoop平台上运行,可以有效进行大数据集聚类分析。
4、基于MapReduce的频繁项集挖掘算法
算法:除Apriori外,还有FPGrowth、Eclat等算法,它们各有特点,如FPGrowth通过构建频繁模式树来减少数据库扫描次数,而Eclat采用垂直数据表示方法优化性能。
并行化方法:这些算法可以通过MapReduce框架实现并行化处理,提高算法在处理大规模数据集时的效率和可扩展性。
MapReduce关联算法和关联预测算法通过发现数据集中的频繁项集和关联规则,为决策提供支持,特别是利用MapReduce框架,使得这些算法能在处理大规模数据集时更加高效,未来研究可以集中在改进这些算法的效率和准确度,以及探索更多的应用场景,以充分利用关联规则挖掘的潜力,对于希望深入了解或应用这些技术的专业人士,建议关注最新的研究进展和开源项目,以获得更多资源和实践经验。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/881652.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复