


在当前信息技术快速发展的背景下,大数据已经成为企业竞争力的核心,本文将深入探讨大数据项目架构的关键环节和层次,以及每个部分的作用和技术组件,帮助读者全面理解大数据项目的构建过程。
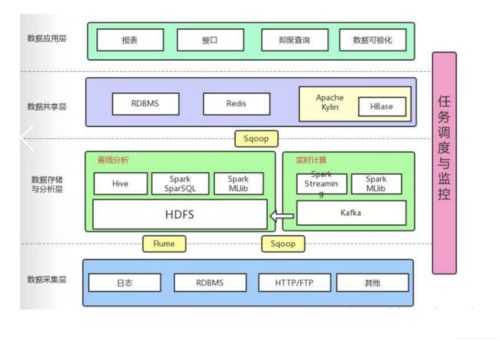

数据采集层
数据采集层是大数据架构中的第一步,它涉及到从多种数据源获取数据的过程,这些数据源可能包括传统的数据库、实时监控系统、社交媒体平台等,此层的主要任务是将原始数据处理成适合存储和进一步分析的格式,常用的数据采集工具包括Apache Kafka和Apache Flume,它们支持处理大规模数据流,确保数据的连续流入和高效管理。
数据存储与分析层
一旦数据被采集,接下来需要将其存储在一个可靠的系统中以供分析和查询,数据存储系统必须能够处理海量数据并支持高速读写操作,Hadoop分布式文件系统(HDFS)和NoSQL数据库如MongoDB和Cassandra在此层中扮演关键角色,数据处理和分析通常利用如Apache Spark和Apache Flink等框架,这些工具提供了高效的数据处理能力,支持批处理和实时数据处理。
数据共享层
数据共享层主要负责管理和优化数据的访问与传输,这一层确保数据可以在不同部门或组织之间安全、快速地共享,使用数据湖架构可以有效地集中和共享数据资源,而数据虚拟化技术则允许用户无需物理移动数据即可访问和整合来自多个源的数据。
数据应用层
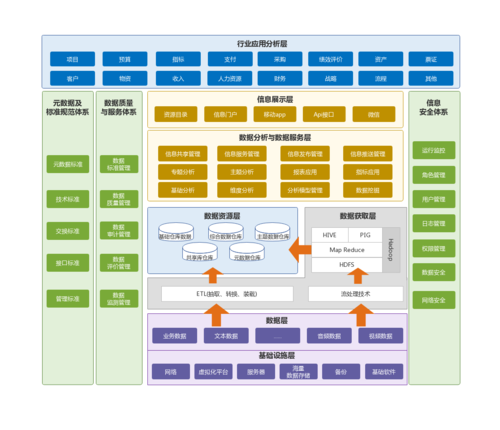
数据应用层关注如何将分析结果转化为实际的业务价值,这包括定制报告、仪表板展示、预测分析和决策支持系统,企业可能使用机器学习模型来预测市场趋势,或者利用图数据库进行客户关系管理,此层的目标是使决策者能够基于数据分析结果做出更明智的商业决策。
相关技术组件
在构建大数据架构时,了解各种可用的技术组件至关重要,以下是一些核心组件及其功能:
Apache Kafka:一个高吞吐量的分布式消息传递系统,用于处理实时数据流。
Apache Hadoop:一个开源框架,支持数据密集型分布式应用程序,通过HDFS存储大规模数据集。
Apache Spark:一个快速的大数据处理引擎,支持批处理和流处理。
MongoDB和Cassandra:NoSQL数据库,适用于处理大量动态生成的数据。
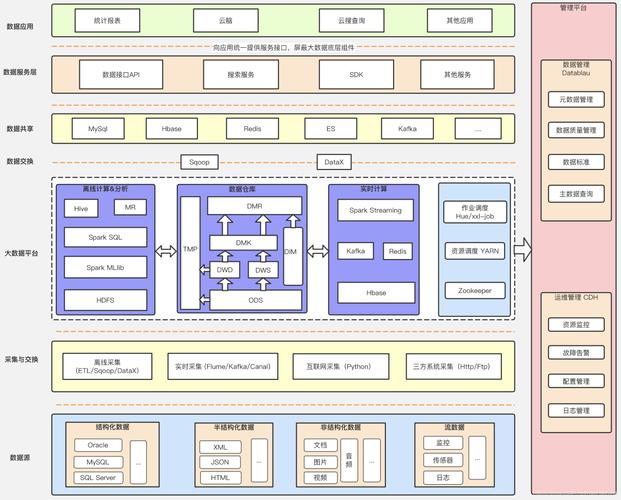
Tableau和Power BI:数据可视化工具,帮助企业制作直观的报告和仪表板。
FAQs
1. 大数据架构设计中最重要的考虑因素是什么?
大数据架构设计时需要考虑的关键因素包括数据的多样性、数据的速度、数据的体积、可扩展性、容错性和安全性,确保架构可以灵活应对数据增长并保护数据免受攻击是至关重要的。
2. 如何选择合适的大数据技术栈?
选择大数据技术栈时,应考虑业务需求、团队技能、预算和现有IT基础设施,评估不同技术的成熟度、社区支持、性能指标和未来的发展潜力也非常关键。
通过对大数据项目架构的详细剖析,我们可以看到,一个成功的大数据解决方案依赖于对各个层次和相应技术组件的精心选择和配置,从数据采集到最终的应用,每一步都需要细致的规划和执行,以确保整个系统的高效、稳定和安全,随着技术的发展,大数据架构也在不断进化,但基本的原则和目标——即实现数据的最大化利用和价值的创造——始终不变。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/881504.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复