

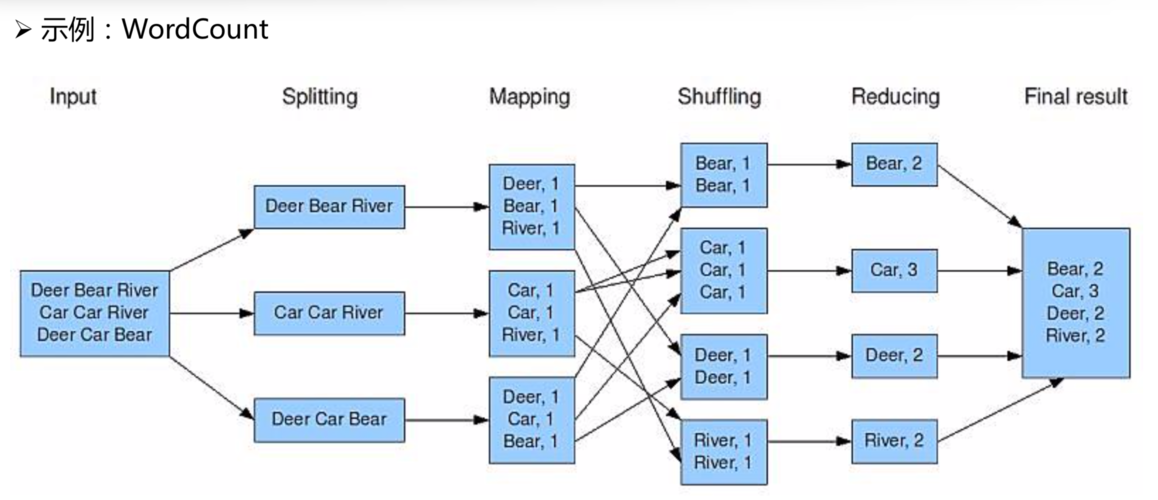
在大数据技术领域,处理和分析大规模数据集是一个重要的挑战,Hadoop MapReduce提供了一个能在大量计算资源上并行处理数据的编程模型,它通过将计算任务分为映射(Map)和归约(Reduce)两个阶段,从而实现对大规模数据集的处理,下文将深入探讨如何利用Hadoop MapReduce计算平均值的问题,并展开讨论其具体实现过程。

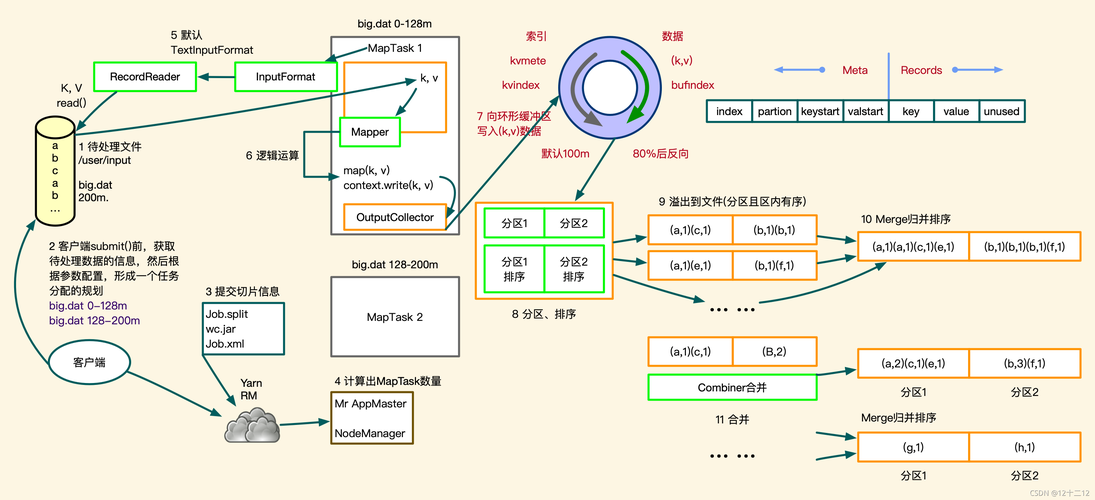
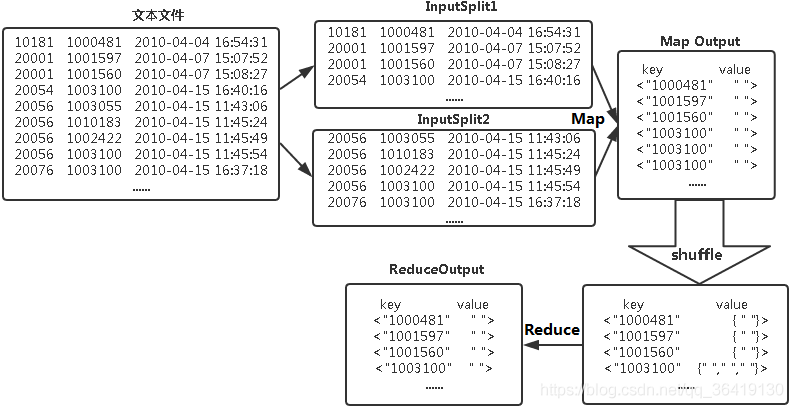
在利用Hadoop MapReduce计算平均值的过程中,需要准备数据输入,通常情况下,数据集存储在HDFS(Hadoop Distributed File System)上,例如路径为/scoreinput/subject_score.csv的文件可能包含学生的学号、各科科目和相应的科目成绩,一行记录代表一个学生的信息,通过这样的数据组织方式,可以方便后续的数据处理操作。
在Map阶段,程序员需要实现Map函数,该函数会处理输入的数据记录,对于成绩平均值的计算来说,可以将每个学生的成绩作为value,而学号或科目作为key进行输出,这个阶段的主要作用是将数据映射到各个reducer上,为后续的规约操作做准备。
接下来是Shuffle阶段,这个阶段是MapReduce框架自动完成的,Shuffle过程的主要目的是将Map函数的输出根据key值进行排序和分组,这样,所有具有相同key值的记录会被划分到一起,形成一个数据集,即进入了Reduce阶段。
Reduce阶段的任务是处理经过Shuffle阶段组织好的数据,在求平均值的场景中,Reduce函数需要对每个key值对应的所有value值进行汇总,然后统计记录数,通过除法运算得出平均值,在MapReduce中,这个过程对应着实现Reduce函数,该函数需要接收Map端输出的键值对,累计同一key的所有value值,并进行平均值的计算。
归纳以上步骤,可以发现使用Hadoop MapReduce来计算平均值涉及数据的切分、映射、混洗、排序和归约等环节,充分体现了MapReduce在分布式计算方面的强大能力和便捷性。
为了加深理解,可以考虑一个实际的例子,假设有一个电商网站需要计算不同商品类别的平均点击次数,首先通过Map函数将每个商品类别和对应的点击次数输出,经过Shuffle阶段将相同商品类别的点击次数聚合在一起,最后在Reduce阶段累计各类别点击次数并计算平均值。
从性能角度考虑,MapReduce框架能够在多个节点上并行处理数据,极大地提高了处理大规模数据集的效率,由于其可扩展性,即便是面对持续增长的数据量,也可以通过增加计算资源来保持处理能力。
Hadoop MapReduce通过其独特的编程模型为处理大数据集提供了有效的解决方案,计算平均值只是众多应用中的一个基础案例,通过掌握其核心思想和方法,可以为更加复杂的数据分析任务提供支持,对于希望深入学习和使用Hadoop MapReduce框架的用户而言,理解这些基本概念和流程是必不可少的。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/880911.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复