


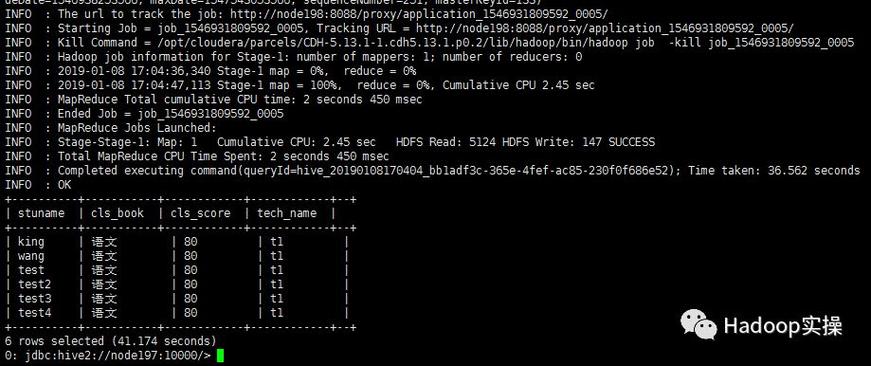
MapReduce作业在解析JSON文件时遇到参数解析错误。这通常是由于JSON格式不正确或解析逻辑存在问题导致的。需要检查JSON数据结构并修正MapReduce代码中的解析逻辑,以确保正确处理JSON数据。
MapReduce解析JSON并替换JSON参数解析错误

(图片来源网络,侵删)
MapReduce是一种编程模型,用于处理和生成大数据集,在处理JSON数据时,可能会遇到解析错误或需要替换某些参数的情况,下面是一个详细的步骤说明,包括小标题和单元表格:
1. 准备环境
确保你已经安装了Hadoop和相关的库,以便使用MapReduce进行数据处理。
2. 编写Mapper函数
Mapper函数负责读取输入的JSON数据,并进行初步的处理,以下是一个简单的Python示例,展示了如何解析JSON数据并替换其中的参数:
import json
def mapper(input_key, input_value):
# 解析JSON数据
try:
data = json.loads(input_value)
except json.JSONDecodeError as e:
print(f"JSON解析错误: {e}")
return
# 替换JSON参数
if 'parameter_to_replace' in data:
data['parameter_to_replace'] = 'new_value'
# 输出键值对
output_key = input_key
output_value = json.dumps(data)
yield output_key, output_value 3. 编写Reducer函数
Reducer函数负责将Mapper的输出进行汇总和处理,在这个例子中,我们不需要对数据进行任何聚合操作,所以可以直接输出:
(图片来源网络,侵删)
def reducer(output_key, values):
# 输出键值对
for value in values:
yield output_key, value 4. 配置MapReduce作业
创建一个MapReduce作业配置文件,指定Mapper和Reducer函数以及输入和输出路径,以下是一个示例配置文件(假设为mapreduce.conf):
{
"mapreduce": {
"mapper": "mapper.py",
"reducer": "reducer.py",
"input": "/path/to/input/data",
"output": "/path/to/output/data"
}
} 5. 运行MapReduce作业
使用Hadoop命令行工具运行MapReduce作业,并指定配置文件:
hadoop jar /path/to/hadoopstreaming.jar n files mapper.py,reducer.py n mapper mapper.py n reducer reducer.py n input /path/to/input/data n output /path/to/output/data n conf mapreduce.conf
6. 检查结果
检查输出目录中的文件,确认JSON参数已被正确替换,如果遇到解析错误,可以查看日志以获取更多详细信息。
(图片来源网络,侵删)
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/880265.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复