


文章归纳

MapReduce和Storm是两种在大数据领域广泛使用的计算框架,它们分别代表了批处理和实时流处理两种不同的数据处理方式,MapReduce适用于大规模的离线数据处理,而Storm则专门用于实时数据分析。
MapReduce模型是由Google提出并首次在Hadoop中实现的一种编程模型,它将计算过程分为两个阶段:Map阶段和Reduce阶段,这种模型非常适合于处理大量的非结构化或半结构化数据,例如网页爬取的内容、日志文件等,MapReduce的一个主要缺点是其处理速度较慢,因为它涉及频繁的磁盘读写操作,数据处理任务在Map阶段完成后需写入磁盘,再由Reduce阶段读取这些中间数据进行处理,最终结果也需要写入磁盘,这一过程中磁盘I/O操作成为了性能瓶颈。
相比之下,Storm是一个专门为实时流处理设计的分布式计算系统,它允许连续的查询和实时的处理,非常适用于需要快速响应的场景,如金融分析、在线警报系统和实时推荐系统等,Storm的主要优势在于其高吞吐量和低延迟,在Storm中,所有的数据处理都是在内存中进行的,这使得处理速度大大加快,Storm支持多种编程语言,为开发者提供了更大的灵活性。
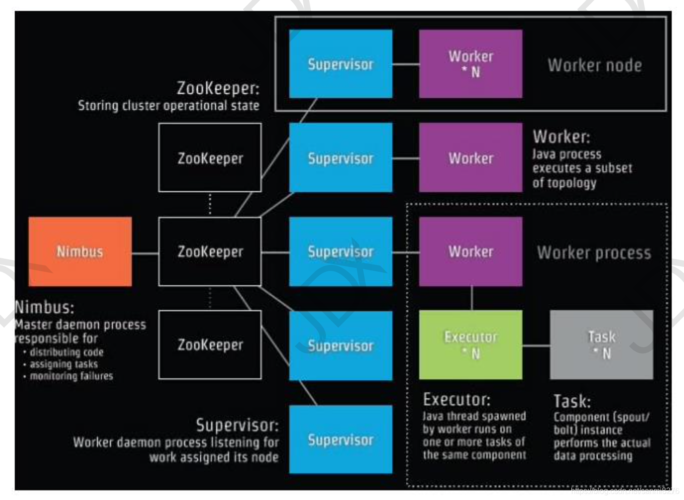
从架构设计上看,Storm与MapReduce有着显著的不同,Storm的核心概念包括Spouts(数据发送者)和Bolts(数据处理者),其中Spouts负责接收数据流,Bolts则处理这些数据流并产生输出流,这种设计使得数据可以在被处理的同时就被传递到下一个处理节点,极大地提高了处理效率和实时性,而MapReduce则是通过分而治之的方式,先将大数据集切分成小块,分别处理后再将结果汇总,这种方式虽然简化了程序的复杂性,但也牺牲了一定的处理速度。
在容错性和可靠性方面,Storm提供了完善的机制来确保每个数据流都被处理,并且可以应对节点故障的情况,Storm会跟踪每个数据流的处理情况,并在出现故障时自动重新分配任务以完成处理,而MapReduce则依赖于Hadoop的文件系统HDFS来进行错误恢复,通过数据的冗余存储来保证数据的完整性,这两种不同的策略反映了它们在处理数据时的时效性和稳定性的权衡。
MapReduce和Storm各有千秋,选择使用哪一个框架取决于具体的业务需求,对于需要处理大量历史数据,且对处理时间要求不高的情况,MapReduce是一个成本效益较高的选择,相反,对于需要快速处理和响应的实时数据分析场景,Storm提供了更优的解决方案,理解两者的基本工作原理和适用场景,可以帮助更好地进行技术选型和数据处理方案设计。

原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/878132.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复