


MapReduce Job分发配置_配置MapReduce Job基线

在大数据时代,处理海量数据已成为企业面临的一大挑战,Hadoop框架下的MapReduce模型提供了一种高效的数据处理方案,本文旨在深入探讨如何配置和分发一个MapReduce Job,确保其能够在分布式环境中高效运行,我们将从作业的依赖管理、配置参数、环境部署等几个关键方面进行详细讨论,并解答一些常见的问题,以助于更好地理解和应用MapReduce技术。
Jar包的创建与管理
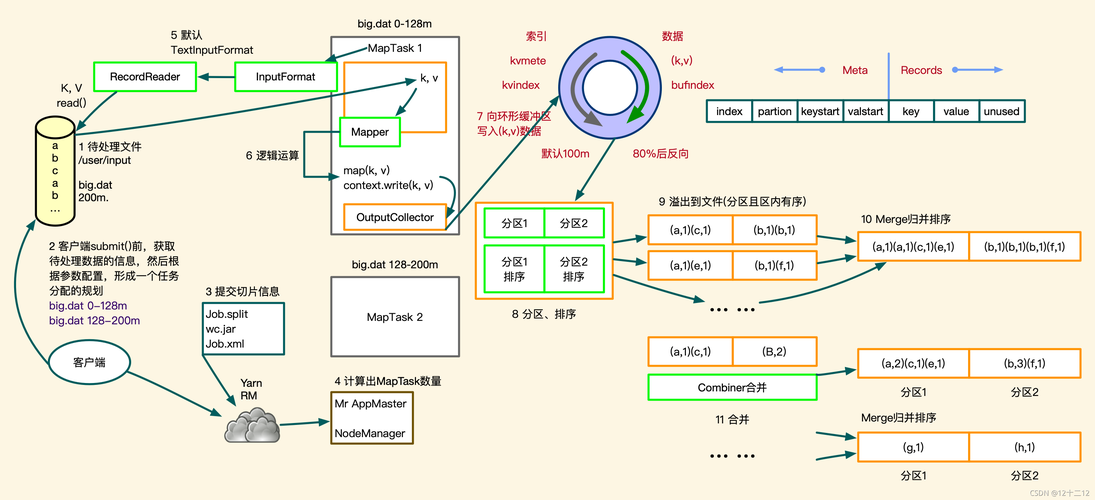
在MapReduce中,所有Mapper、Reducer以及相关依赖通常被打包成一个JAR文件,这个JAR文件的配置是作业分发的关键一步,通过将代码及其依赖打包成JAR,可以确保在集群中的每一台机器上都能正确执行作业的各个任务,如果作业需要访问额外的资源或服务,相关的配置文件也应包含在内,这可以通过mapreduce.job.jar参数实现,正确的依赖和资源管理不仅能减少分发和加载时间,还能避免运行时错误,提高作业执行的稳定性和效率。
核心配置参数
MapReduce作业的核心配置通过几组XML文件进行,包括coresite.xml、hdfssite.xml和mapredsite.xml,这些配置文件控制着Hadoop的行为,如作业的输入输出格式、Map和Reduce的任务数量、内存限制等。mapredsite.xml专门用于设置MapReduce任务的相关参数,如Map和Reduce任务的数量可以通过mapreduce.job.maps和mapreduce.job.reduces来定义,合理配置这些参数对于优化作业性能、管理资源消耗具有重要意义。
YARN上的部署与管理
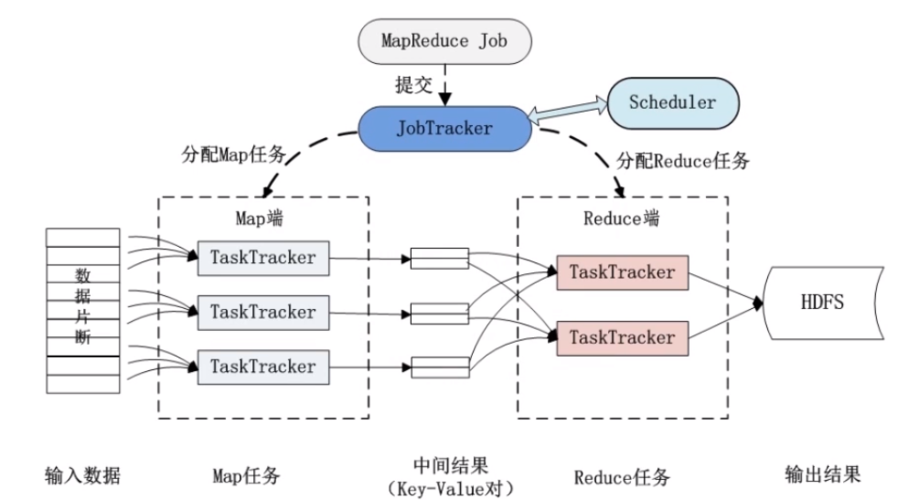
虽然MapReduce本身不启动独立进程,但其运行依赖于YARN的资源调度和管理,YARN中的ResourceManager负责整个集群的资源分配,而NodeManager则负责每个节点的任务执行,理解YARN的工作原理和相关配置可以帮助更有效地管理MapReduce作业的资源需求,如通过调整YARN容器的大小来适应特定的MapReduce任务,监控YARN上的MapReduce作业状态也是确保作业健康运行的重要手段。
环境部署与监控
部署Hadoop及MapReduce作业前,必须确保HDFS的正确配置和运行,NameNode和DataNode的健康状态直接影响到MapReduce作业的数据存取速度和可靠性,监控工具如Ganglia可用于监视集群的资源使用情况和作业的运行状态,帮助及时发现并解决可能的问题。
常见问题FAQs
Q1: 如何解决MapReduce作业中的依赖冲突?
A1: 依赖冲突常常是因为不同的作业使用了不同版本的库或者有相同的类名造成的,为避免这种情况,可以在构建JAR时进行依赖检查,确保所有依赖库的版本兼容性,并使用类似Maven或Gradle的工具管理依赖关系,确保作业中使用的自定义类具有唯一的包名和类名,以避免命名冲突。
Q2: 如何优化MapReduce作业的执行效率?
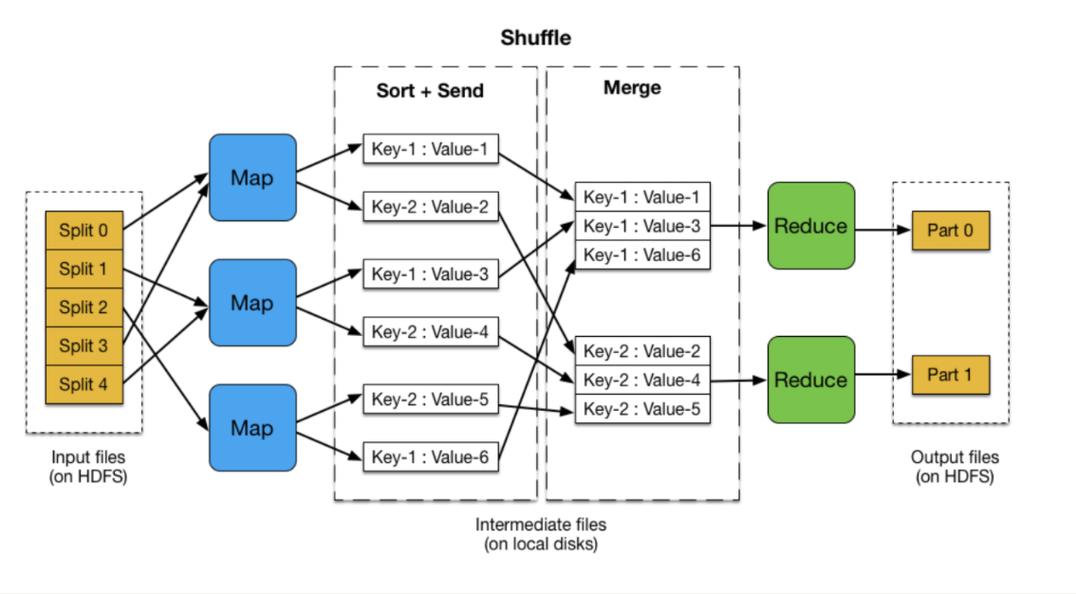
A2: 优化MapReduce作业的效率可以从多方面入手:合理设置mapreduce.job.maps和mapreduce.job.reduces参数,根据数据量和集群规模调整Map和Reduce任务的数量;优化数据输入格式和存储方式,使用合适的压缩算法减少数据传输量;监控作业执行情况,分析日志中的瓶颈,并根据反馈调整配置或代码。
通过上述各方面的策略和建议,可以有效地配置和管理MapReduce Job的分发,确保作业在分布式环境中高效、稳定地运行,在大数据项目中,合理利用这些策略不仅可以提升数据处理能力,还可以节省成本和时间,为企业带来更大的价值。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/877886.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复