


在MySQL数据库中,自增ID是一种常用于创建唯一标识符的机制,本文将详细介绍MySQL数据库中的自增ID,包括其作用、实现方式、优缺点以及可能遇到的问题和解决方案,具体内容如下:

1、自增ID的作用
唯一性保证:自增ID能够为每条新记录生成一个唯一的标识符,确保数据表中的每条记录都能被准确地识别和区分。
简化操作:自动生成的ID减少了用户或应用程序在插入数据时需要手动指定ID的麻烦,简化了数据的插入过程。
2、自增ID的实现方式
默认行为:在MySQL中,当一个字段被定义为AUTO_INCREMENT属性,每新增一条记录,该字段的值就会自动递增。
自定义设置:用户可以在创建表时通过AUTO_INCREMENT关键字指定某个字段为自增ID,也可以指定起始值和增量。
3、自增ID的优点
简单高效:自增ID的生成和管理由数据库系统内部优化,通常具有较高的效率。
易于理解:自增ID通常是顺序排列的整数,这符合人们对于编号的直观理解。
4、自增ID的缺点及问题
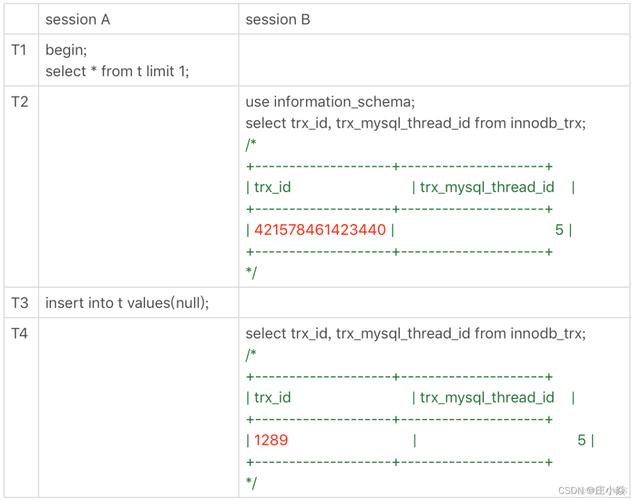
存储限制:自增ID可能会因为超出数据类型的存储范围而导致插入失败。
隐私泄露风险:由于自增ID是连续的,外部用户可能通过ID推测出其他记录的信息,存在一定的隐私泄露风险。
5、自增ID与UUID的比较
空间占用:相比自增ID,UUID使用更多的存储空间(128位),而自增ID通常使用32位或64位整数。
应用场景:UUID适用于分布式系统和需要全局唯一标识符的场景,而自增ID更适合单一数据库应用。
6、自增ID的常见问题及解决方案
插入ID自增为2的问题:在某些情况下,MySQL的auto_increment主键ID在插入时自增为2,这可能是由于innodb_autoinc_lock_mode参数设置不当导致的。
解决办法:可以通过调整innodb_autoinc_lock_mode参数的值来解决自增步长不为1的问题。
7、自增ID的优化建议
合理预估ID范围:根据实际数据量和增长速度,选择合适的数据类型和起始值,避免ID超出范围。
使用分区表:对于非常大的数据集,可以考虑使用分区表来管理自增ID,以提高效率和可维护性。
MySQL数据库中的自增ID是一种方便且高效的主键生成策略,它能够自动为新插入的行生成唯一的标识符,自增ID也存在存储限制和隐私泄露等问题,需要根据具体的应用场景和需求来权衡是否使用,在实际应用中,开发者应当注意自增ID的配置和优化,以确保数据库系统的稳定运行和数据的安全。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/877611.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复