


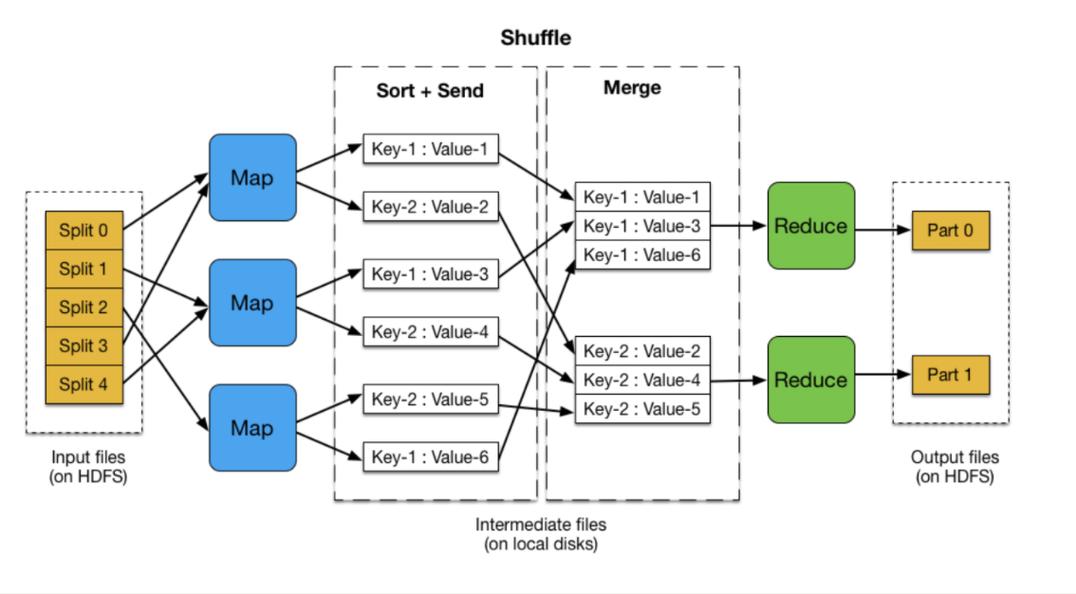
MapReduce是大数据处理领域的一个重要概念,尤其在分布式计算环境下展现出其强大的数据处理能力,作为一个编程模型,它通过两个主要的阶段,即Map阶段和Reduce阶段,来处理和生成大规模数据集,这种模型在Hadoop框架下得到了广泛应用,并已成为处理海量数据问题的一个标准工具。
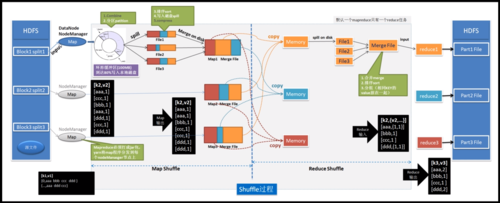

MapReduce的核心功能是将用户编写的业务逻辑代码与自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上,这种分布式运算程序的编程框架极大简化了开发者的工作,使得原本复杂、需在多台机器上运行的程序开发变得像编写单串行程序一样简单,当计算资源需求增加时,MapReduce也展现出良好的扩展性——只需简单地增加机器即可扩展其计算能力。
MapReduce的应用极大地促进了大数据分析的发展,在互联网、金融、医疗以及政府等各个领域,都可见到其身影,互联网公司利用MapReduce处理海量的日志文件,从中挖掘用户行为模式;金融机构通过MapReduce分析交易数据,用于风险控制和欺诈检测;在医疗领域,MapReduce帮助研究人员处理复杂的基因组数据,加快新药的研发进程。
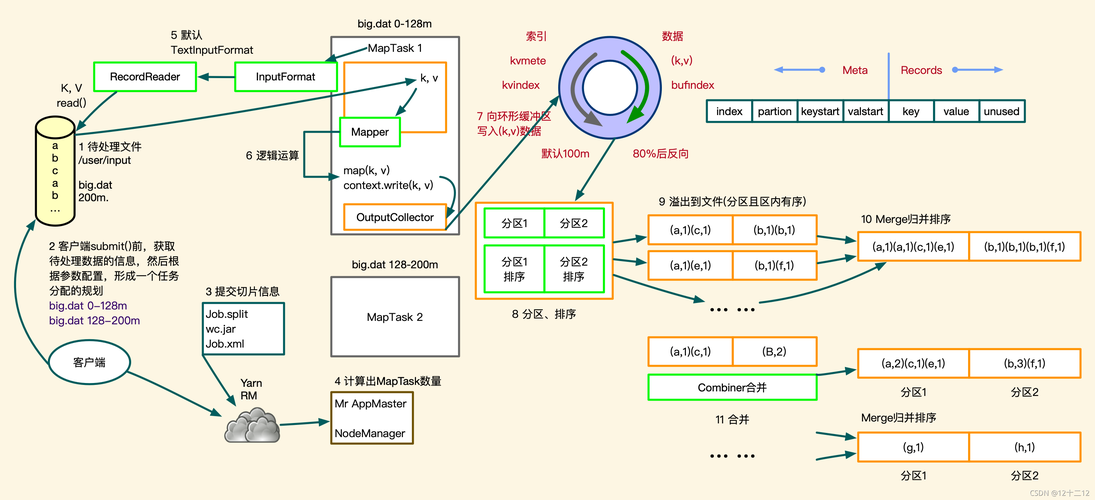
值得一提的是,学习和应用MapReduce技术时,有一些信息需要特别关注,初学者可能会对MapReduce的工作原理和应用场景有所疑惑,MapReduce本质上是一个分而治之的策略,应用于分布式系统,以实现对大量数据的处理,由于其高效的容错机制和简化的编程接口,MapReduce能够有效地处理大规模数据集,了解这些核心概念有助于更好地掌握和应用MapReduce技术。
可以清晰地认识到MapReduce作为一项关键技术,其在数据处理和分析领域的重要作用,无论是面对海量数据的日常处理,还是满足特定的业务分析需求,MapReduce都提供了一种高效、可靠的解决方案,随着技术的不断发展和应用的不断深入,MapReduce将继续在各行各业扮演着不可或缺的角色。
FAQs
1. MapReduce适合解决哪些类型的问题?
MapReduce特别适合于数据密集型和非实时性的批量处理任务,如日志分析、推荐系统的协同过滤、网页索引构建等。
2. 如何开始学习MapReduce?
推荐从理解其基本工作原理入手,结合具体的编程语言(如Java、Python)实践编写Map和Reduce函数,逐步深入到框架(如Hadoop)的使用和优化策略。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/877544.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复