


在当今大数据时代,词频统计作为一种基础且普遍的数据处理需求,常用于文本分析、数据挖掘和搜索引擎优化等领域,MapReduce模型,由Google提出并广泛应用于大规模数据集的处理,提供了一个高效的框架来执行词频统计,下面将详细解析使用Hadoop平台下的MapReduce进行词频统计的整个过程。

需要做的是准备工作,包括实验环境的搭建和数据的预处理,实验环境通常配置在Linux操作系统下,使用已安装好的Hadoop伪分布式环境,确保Hadoop服务正在运行,这可以通过输入特定的启动命令来完成,准备要处理的数据文件,通常是文本格式,存放在HDFS(Hadoop Distributed File System)上可访问的路径下。
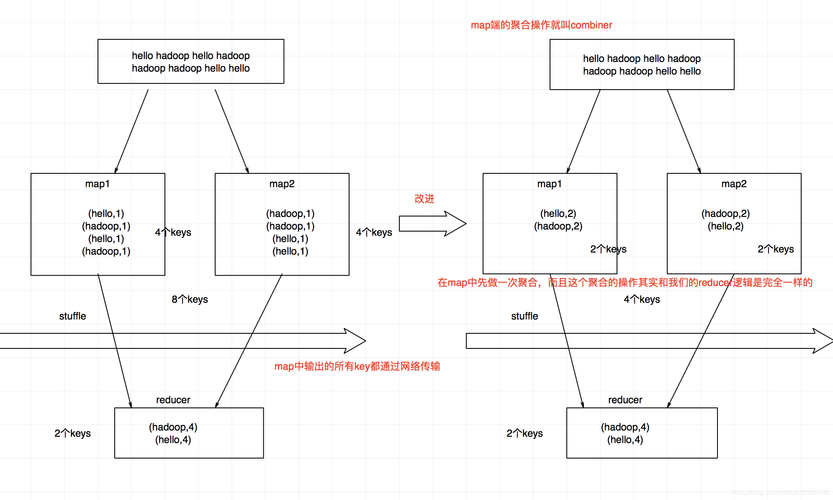
开发MapReduce作业的核心部分:Mapper和Reducer函数,在Mapper阶段,程序会读取文本文件,并按行将数据切片,把每一行内容交给Mapper处理,Mapper的任务是读取每一个单词,并为每个出现的单词生成一个中间键值对<单词,1>,这个过程通过Java代码实现,经常使用到的数据结构有HashMap等。
紧随其后的是Shuffle和Sort阶段,这是MapReduce框架自动完成的,在这一阶段,框架会将所有Mapper的输出按键(单词)进行排序,并将所有相同键的值(数字1)聚集到一起,为下一阶段的归约操作做准备。
在Reducer阶段,每个单词和其对应的数字列表会被传递给Reducer,Reducer的任务是计算每个单词的频率,即对每个单词的数字列表求和,得出该单词的总出现次数,结果会输出到HDFS上指定的目录中。
为了更深入地理解整个流程,可以通过一些实际的例子来观察数据的流动和变化,如果输入文件中包含如“apple banana apple orange banana apple”这样的文本,Mapper可能会输出如下键值对:<"apple", 1>, <"banana", 1>, <"orange", 1>,经过Shuffle和Sort后,相同的键(单词)会被分组到一起,Reducer会将这些键值对归约为:<"apple", 3>, <"banana", 2>, <"orange", 1>。
执行MapReduce作业,这通常涉及编译Java代码,打包成JAR文件,通过Hadoop命令行工具提交作业到集群,并监控其运行状态直至完成。
通过这个流程,可以高效地处理海量文本数据,统计出各个单词的出现频率,在实际操作中,还需要注意一些细节问题,比如输入数据的预处理、程序的容错性以及性能优化等方面。
相关FAQs:
1、问: MapReduce程序运行缓慢,如何优化?
答: 可以尝试以下方法优化:增加更多的计算资源(如增加节点、提高硬件性能),优化数据存储格式以减少I/O开销,调整MapReduce参数(如内存分配、并发任务数),以及优化算法本身减少不必要的计算。
2、问: 如果遇到大量小文件,应如何处理以提高性能?
答: 处理大量小文件时,可以考虑预先合并这些小文件,以减少MapReduce任务启动的次数和时间,使用Hadoop的CombineFileInputFormat可以有效解决小文件问题,它能够将多个小文件组合成一个切片,从而提高处理效率。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/876296.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复