


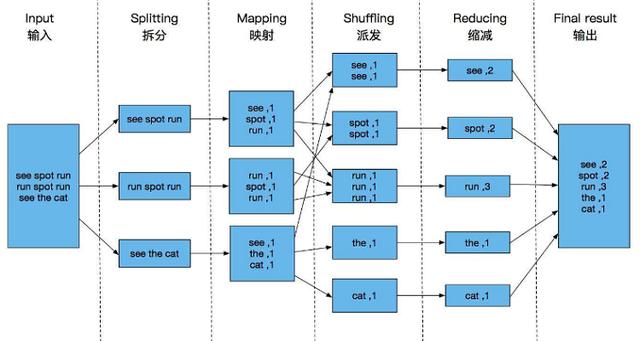
在MapReduce框架中,排序是一个至关重要的操作,无论是在MapTask还是ReduceTask阶段,数据都会按照key进行排序,这是Hadoop框架的默认行为,下面将详细解析MapReduce中的排序机制,包括Map阶段的局部排序、Shuffle和Sort阶段的全局排序,以及Reduce阶段的处理过程:
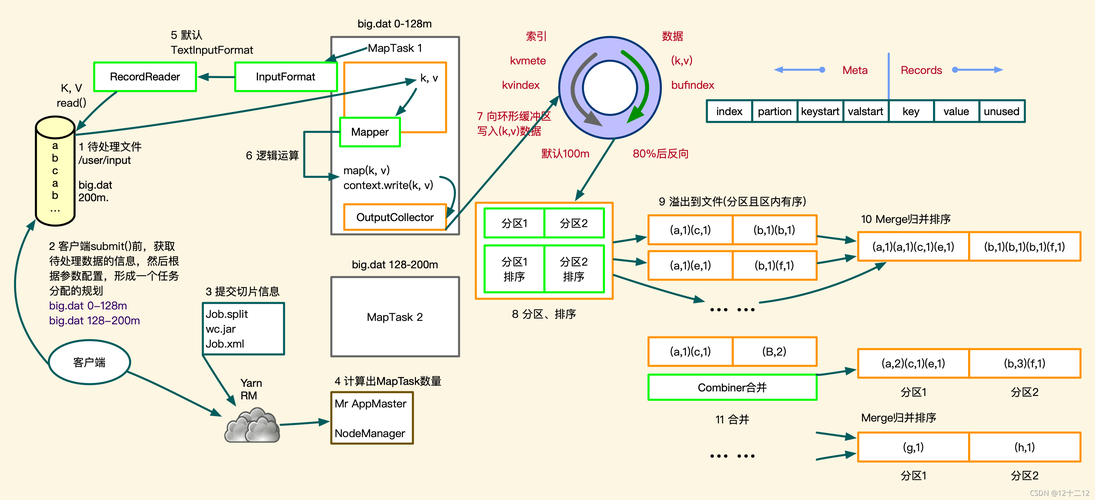

1、Map阶段的局部排序
环形缓冲区的使用:MapTask先将处理结果存放在一个称为环形缓冲区的地方,当该缓冲使用达到一定阈值后,会对其中的数据执行快速排序。
溢写到磁盘:经过初步排序后的数据随后会被溢写到磁盘上,全部数据处理完毕之后,MapTask会对磁盘上的所有文件进行一次归并排序,以确保数据整体有序。
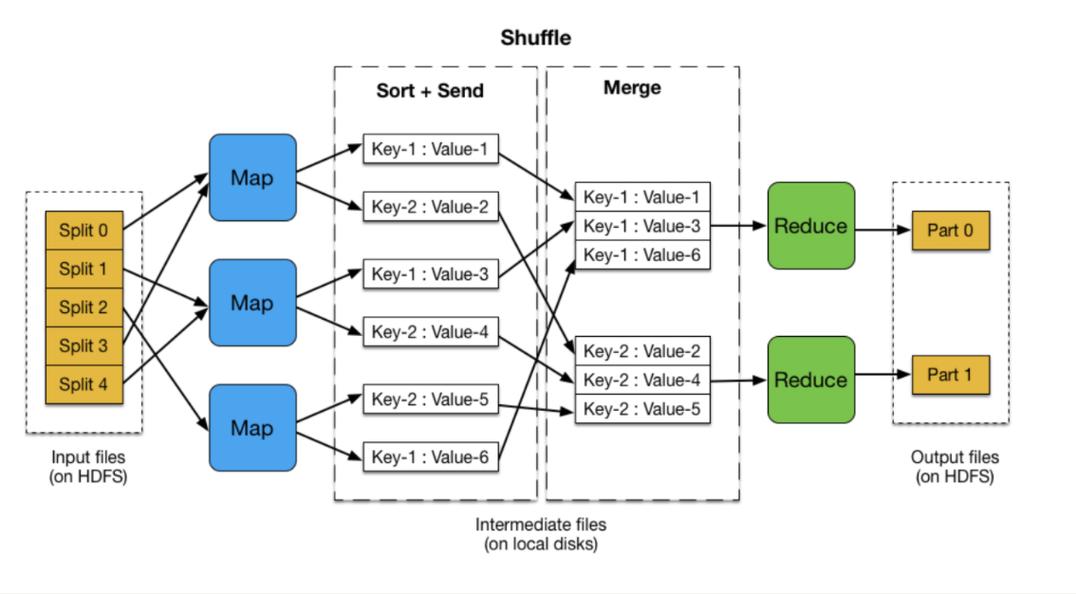
2、Shuffle和Sort阶段的全局排序
Shuffle过程:输出文件按照Partitioner的算法被分成R个分区,每个ReduceTask负责一个分区的数据。
全局排序:在Reduce侧,每个ReduceTask会对其负责的分区数据进行归并排序,确保送入Reduce函数的数据是有序的。
3、Reduce阶段的排序
输入数据的顺序性:进入ReduceTask的数据已经是有序的,这使得Reducer可以很方便地对数据进行处理。
自定义排序逻辑:如果应用需要特定的排序方式,可以通过实现自定义的比较器(Comparator)来改变排序逻辑。
考虑到排序操作对性能的影响,有几点需要注意:
合理设置MapTask的数量,以平衡每个MapTask处理的数据量,避免个别MapTask因处理大量数据而成为性能瓶颈。
在I/O操作频繁的场景下,优化磁盘读写速度可能提升整体MapReduce作业的性能。
MapReduce框架中的排序机制不仅保证了数据处理的顺序性,也为数据的高效处理提供了支持,了解这些内部机制有助于更好地理解和应用MapReduce技术,在处理大规模数据时发挥其优势。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/876206.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复