


在分布式系统设计中,读写分离是一项关键的优化技术,本文将深入探讨读写分离的概念、实现方式及其在不同场景下的应用效果。

读写分离的原理与实现
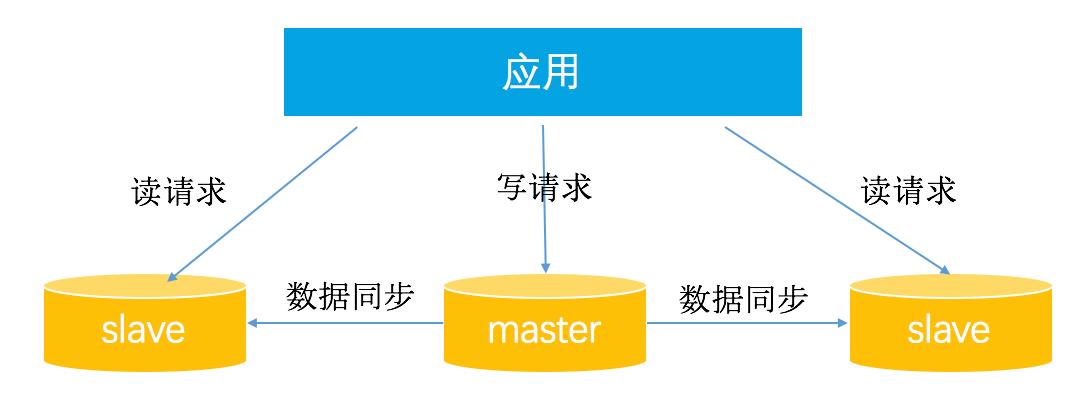
读写分离的基本原理是将数据库操作中的“读”和“写”分配到不同的服务器上执行,以平衡负载并提高数据库的整体性能和可用性,在分布式环境中,这一策略尤为重要,因为数据访问请求可能会大幅增长,单个数据库实例难以承担所有负载。
主从复制模式
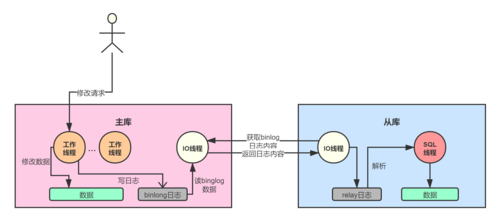
主从复制是实现读写分离的一种常见方法,在这种模式下,所有的写操作都发送到主数据库(Master),而读操作则分发到多个从数据库(Slave),通过这种方式,写操作的高延迟不会影响读操作的性能,同时从库可以水平扩展,增加系统的读能力,这种模式适用于读密集型的应用,可以显著减少对主库的压力。
使用中间件实现读写分离
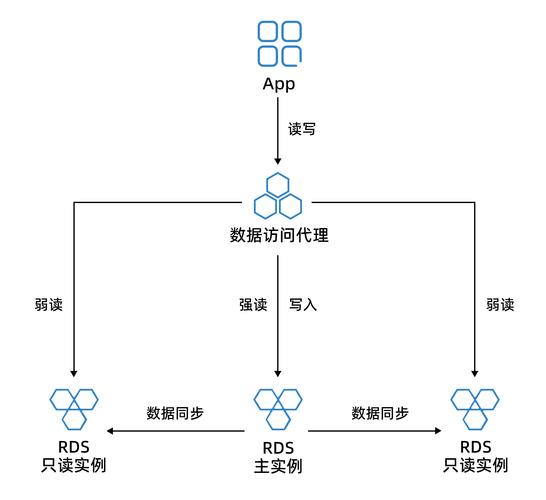
为了更高效地管理读写分离,通常需要依赖一些中间件工具,如Mycat和dble,这些工具能帮助应用服务器透明地连接不同的数据库实例,自动处理读写分离的逻辑,Mycat是基于Cobar开发的产品,支持强大的数据分片、读写分离等功能,适用于大规模数据处理的环境。
应用场景与案例分析
读写分离虽然是一种有效的优化策略,但并不是所有场景都适用,以下是一些典型的应用场景及其分析:
高读取需求的应用场景
对于新闻网站、电商产品展示等主要涉及内容展示的平台,用户读取信息的请求远多于写入,在这样的场景下,读写分离可以显著提高网站的响应速度和处理能力,通过将从库数量的增加,可以几乎无限扩展读操作的处理能力,满足大量并发访问的需求。
不适宜使用读写分离的场景
对于金融交易或实时数据处理这类写操作频繁且需要即时一致性的应用,读写分离可能不是最佳选择,在这些场景中,写操作的性能和数据一致性的要求非常高,使用传统的关系型数据库或其他高性能存储方案可能更为合适。
优势与挑战
读写分离带来的优势包括:
提高性能:通过分散读写请求到不同的服务器,减轻了单个数据库的压力,提高了查询效率。
增强可扩展性:可以根据需求动态调整从库的数量,以应对不同的访问压力。
提升可用性:即使主库出现问题,从库仍能处理读请求,保证服务的持续性。
面临的挑战包括:
数据同步延迟:主从复制可能存在延迟,导致读操作获取的数据不是最新的。
复杂性增加:引入读写分离增加了系统的复杂度,需要有效管理和维护主从数据库间的关系。
成本增加:需要维护多套数据库系统,增加了硬件和运维的成本。
相关FAQs
Q1: 读写分离是否适合所有类型的数据库系统?
A1: 读写分离主要适用于关系型数据库系统,尤其是那些支持主从复制的系统,如MySQL和PostgreSQL,对于NoSQL数据库,由于其本身设计上的可扩展性和分布式特性,不一定需要采用读写分离策略。
Q2: 如何确保读写分离配置的正确性和高效性?
A2: 首先需要确保数据库的主从复制正确设置,无数据丢失和错误同步的情况,使用合适的中间件来管理连接池和路由规则,定期进行性能测试和优化,确保读写分离的实际效果符合预期。
读写分离是一个强大但需要谨慎实施的策略,正确的应用和优化可以使数据库系统更加健壮和高效,但也需要面对由此带来的技术挑战和成本问题。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/875702.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复