


设计MapReduce ETL处理,不仅需要合理规划数据的提取、转换和加载流程,还需考虑到数据映射的精确性和高效性,在ETL映射设计中,要确立源数据与目标数据仓库之间的正确关联关系,这涉及到对数据结构、类型、格式及语义的深入理解,下面将详细探讨如何利用MapReduce进行高效的ETL工作:
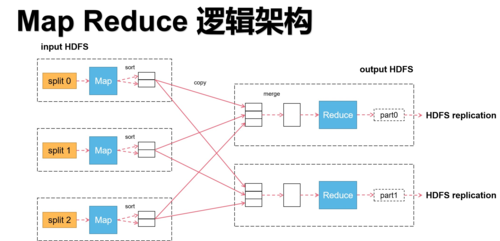

1、ETL过程
Extract(抽取):从不同的数据源中提取数据,这些数据源可以是数据库、文件等。
Transform(转换):包括数据清洗、数据合并等操作,将原始数据处理成一致的格式。
Load(加载):将处理后的数据载入目的地,如数据仓库或其他数据库。
2、MapReduce角色定位
Mapper任务:执行数据抽取和转换操作,如清洗个别文件中的错误数据或格式不一致问题。
Reducer任务:负责数据的最终聚合和加载,通常在数据已通过Mapper处理后进行。
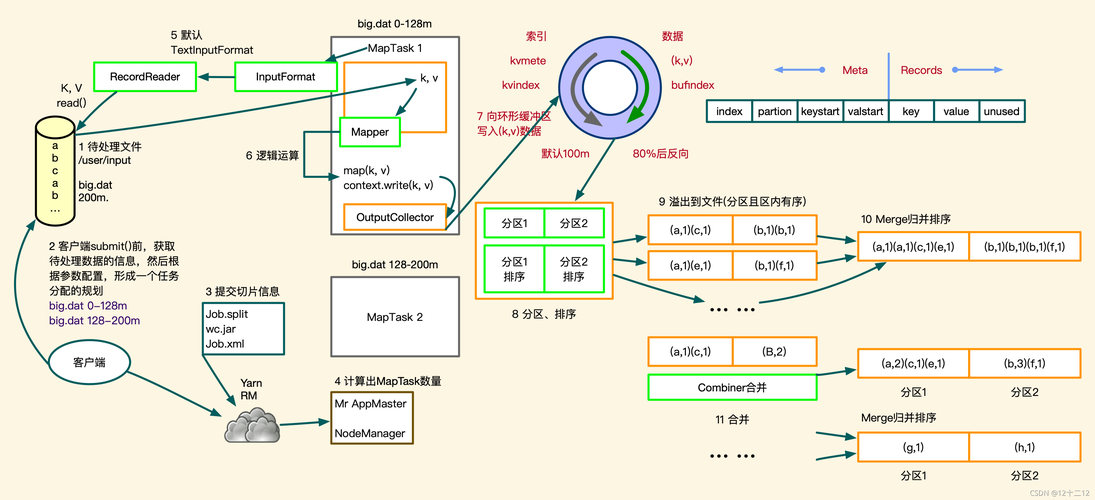
3、关键步骤详解
数据解析与清洗:识别文件中各基站编号,并将其添加到数据中;统一各字段间的分隔符,确保数据格式的一致性。
数据映射设计:定义源数据与目标数据仓库间的映射规则,包括数据名称、类型、格式等对应关系。
编程实现:编写MapReduce程序,其中Mapper负责数据清洗,Reducer(如果需要)负责数据的最终聚合。
4、注意事项
数据质量控制:确保数据准确性,避免因格式错误或不完整数据导致的问题。
性能优化:考虑数据处理的效率,尤其在大数据环境下,优化MapReduce作业的运行时间和资源消耗。
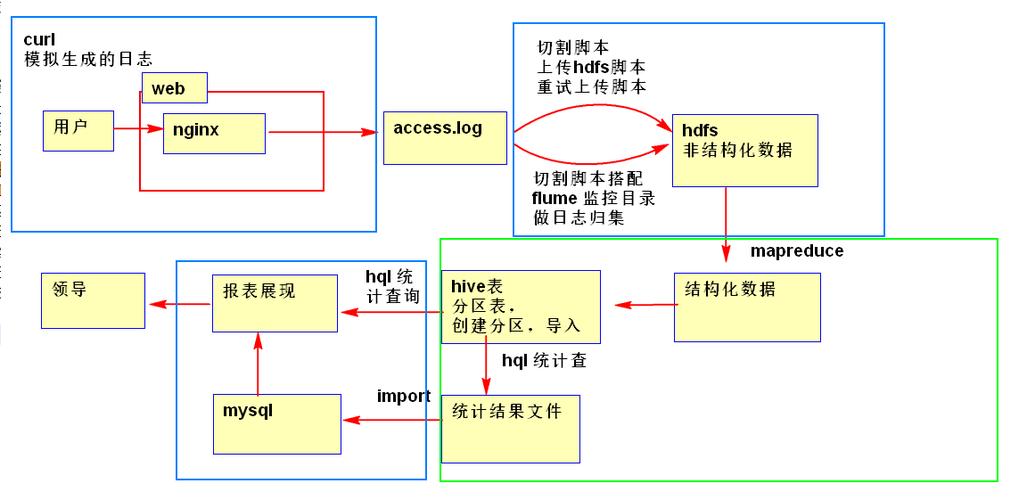
容错机制:设计时需考虑数据的备份和恢复策略,以防数据丢失或损坏。
5、具体案例分析
基站编号添加实例:如文件名“450010999992000”含基站编号“45001”,需要在数据中添加此编号。
数据清洗实例:去除日志中字段个数不符合要求的记录,例如字段个数小于等于11的日志应被清除。
MapReduce为处理大规模数据集提供了有效的框架,特别是在数据清洗和转换方面显示出其强大的能力,通过上述步骤和注意事项的指导,可以完成从原始数据的抽取到转换后数据的加载全过程,确保数据质量和高效性,在实际设计过程中,还可以根据具体需求调整和优化MapReduce任务,以适应不同的数据处理场景。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/875598.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复