


在探讨MapReduce与KMeans算法结合的实现方式时,可以发现这种融合为处理大规模数据集提供了有效的解决方案,下面将深入解析这一算法的步骤、特点以及具体如何在MapReduce框架下实现:
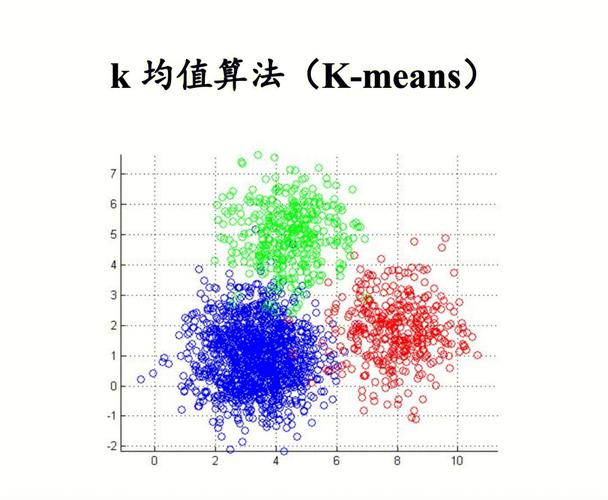

KMeans 算法基础
1、算法流程
初始化:确定K个初始质心,这些质心可随机选择或基于某种启发式方法确定。
分配数据点:每个数据点被分配给最近的质心,形成初步的簇。
更新质心:根据现有簇中的数据点,重新计算质心的位置。
迭代优化:重复上述分配和更新步骤,直到质心的位置变化小于预设的阈值或不再变化。
2、距离函数
欧氏距离:KMeans算法通常使用欧氏距离来计算数据点与质心之间的相似度。
3、算法优点
简单高效:KMeans算法因其算法逻辑简单且易于实现而广泛应用。
伸缩性:能够处理不同规模和维度的数据集合。
4、算法挑战
初始质心敏感:算法结果可能受到初始质心选择的影响。
局部最小值问题:可能会收敛到局部最优而非全局最优。
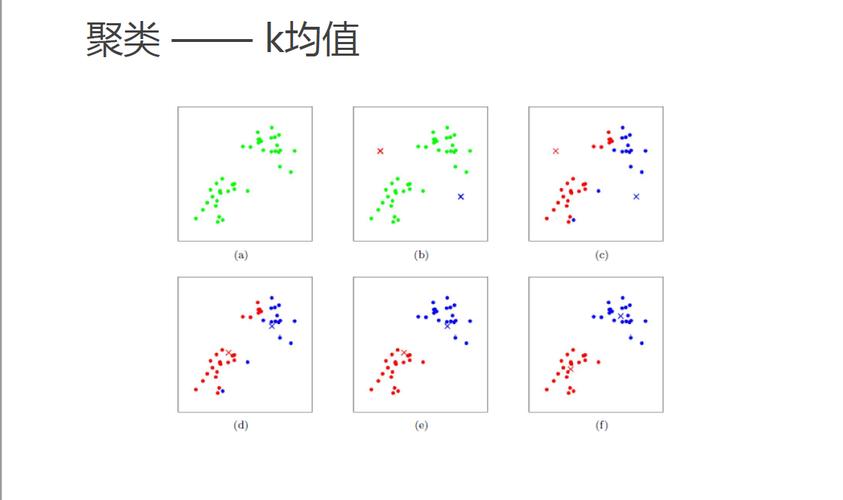
MapReduce 实现 KMeans 算法
1、MapReduce简介
概念理解:MapReduce是一种编程模型,用于大规模数据处理。
优势分析:通过并行处理加快数据处理速度,并可扩展至大量机器。
2、MapReduce的角色
Mapper的任务:每个Mapper处理一部分数据,计算每个数据点到各质心的距离,并输出数据点及其最近的质心标识。
Reducer的责任:Reducer汇总所有Mapper的输出,按质心归类数据点,并计算新的质心位置。
3、具体操作步骤
读取和初始化质心:在MapReduce作业开始前,先读取存储在HDFS中的初始质心。
Map阶段:Mapper读取数据点,并与质心进行比较,输出最近质心作为Key,数据点作为Value。
Reduce阶段:Reducer接收相同Key的数据点集,计算平均值,得到新的质心,并将新旧质心对比,判断是否继续迭代。
4、迭代与终止条件
迭代过程控制:通过控制程序来初始化质心,并迭代调用MapReduce作业直到满足终止条件。
终止条件设置:当质心的变化小于预设阈值或无显著变化时,停止迭代。
5、数据共享和管理
HDFS的作用:利用HDFS进行中心点的存储,以实现各节点间的数据共享。
数据清空与写入:每次迭代后,根据需要更新质心文件,并管理中间结果的存储。
转向具体的实践细节和注意事项,当实际操作MapReduce与KMeans算法的结合时,需要考虑以下要点:
确保数据的预处理得当,以便算法能高效执行。
仔细选择初始质心,有时错误的初始选择可能导致不理想的聚类结果。
监控迭代过程中的资源消耗,以避免过度消耗集群资源。
评估不同参数设置对算法结果的影响,以找到最佳配置。
归纳而言,KMeans算法通过MapReduce的并行处理能力获得了在处理海量数据集上的应用可能性,在实施过程中,不仅要考虑算法本身的细节,还要关注系统资源的管理以及迭代过程中的效率优化,通过不断调整和完善,可以在大数据环境下实现高效、准确的数据聚类。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/875543.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复