


基于Python语言实现MapReduce的具体实例
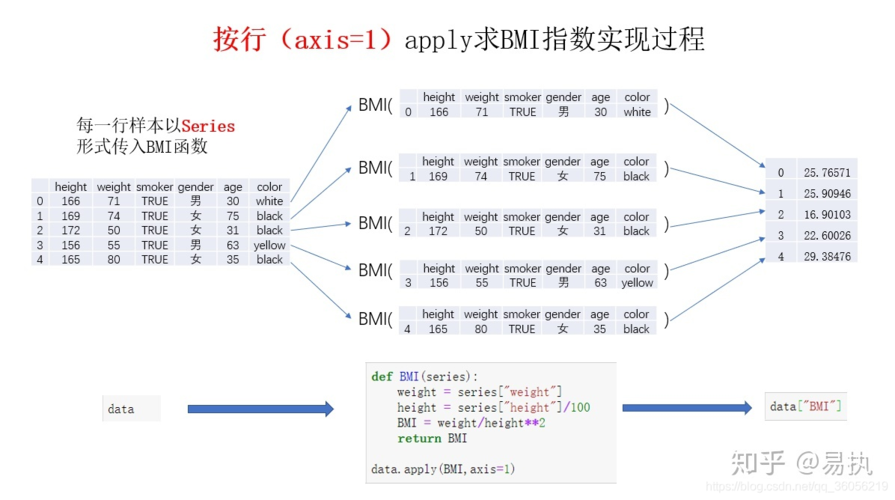

MapReduce是一种分布式计算模型,由Google提出,用于处理大规模数据集,其核心思想是将计算作业分解为映射(Map)和归纳(Reduce)两个阶段,从而实现高效的数据处理,下面将通过一个简单的例子来展示如何使用Python编写和运行一个MapReduce任务,具体地统计输入文件中单词的频率。
实验环境
在开始编写代码之前,需要准备实验环境,确保系统中已安装Python和Hadoop,为了在Hadoop上运行Python脚本,还需要有Hadoop Streaming工具。
Map阶段处理脚本
1、Mapper脚本编写:
Mapper的任务是读取输入文件,并输出单词及其出现次数的键值对。
使用Python标准库中的sys.stdin进行逐行读取。

对每行文本进行分词,生成每个单词及其频次。
2、:
import sys
for line in sys.stdin:
words = line.strip().split()
for word in words:
print('%st%s' % (word, 1))
3、本地测试:
可以使用UNIX管道对脚本进行本地测试。
通过echo "test test mapreduce" | python mapper.py命令,应得到每个单词及其计数1。
Reduce阶段处理脚本
1、Reducer脚本编写:
Reducer的任务是汇总Mapper输出的键值对,累计同一单词的频次。
同样使用sys.stdin来读取Mapper的输出。
对输入进行字典统计。
2、:
from collections import defaultdict
word_count = defaultdict(int)
for line in sys.stdin:
word, count = line.strip().split('t')
word_count[word] += int(count)
for word, count in word_count.items():
print('%st%s' % (word, count))
3、本地测试:
同样可以使用UNIX管道测试Reducer。
模拟Mapper输出多行相同单词,测试Reducer是否能正确汇总。
集群运行测试
1、Hadoop Streaming工具应用:
Hadoop Streaming允许使用任何可执行程序或脚本作为Mapper和Reducer。
需要将Mapper和Reducer脚本上传到Hadoop集群。
2、运行测试:
使用Hadoop Streaming命令运行作业,并指定Mapper和Reducer脚本。
观察输出是否符合预期。
3、存在的问题及解决:
编码格式问题:确保Hadoop集群中的所有节点使用相同的文件编码。
权限问题:可能需要设置脚本的执行权限。
实验归纳
通过以上步骤,可以完成一个基本的Python MapReduce实例,这个例子虽然简单,但展示了MapReduce模型处理大数据的核心思想,对于更大规模的数据处理需求,可以考虑增加更多的Map和Reduce任务,以及优化脚本以处理复杂的数据结构。
使用Python实现MapReduce不仅降低了开发难度,还增加了处理大规模数据集的灵活性,希望以上内容对您有所帮助,并能在实际场景中得到有效应用。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/875413.html
 微信扫一扫
微信扫一扫