


MapReduce 项目通常用于处理和生成大数据集,它是由两个阶段组成的编程模型:Map 和 Reduce,下面是一个详细的 MapReduce 项目示例,包括小标题和单元表格。

项目背景
假设我们需要统计一个大型文本文件中每个单词的出现次数,文本文件可能非常大,无法一次性加载到内存中进行处理。
项目步骤
1、数据输入
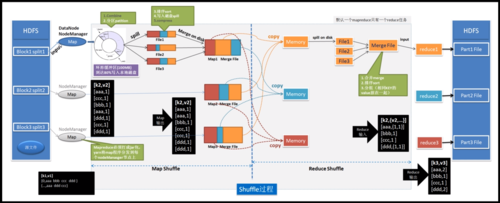
2、Map 阶段
3、Shuffle 阶段
4、Reduce 阶段
5、数据输出
数据输入
输入:一个大型文本文件,包含多个单词和句子。
输出:单词及其出现次数。
Map 阶段
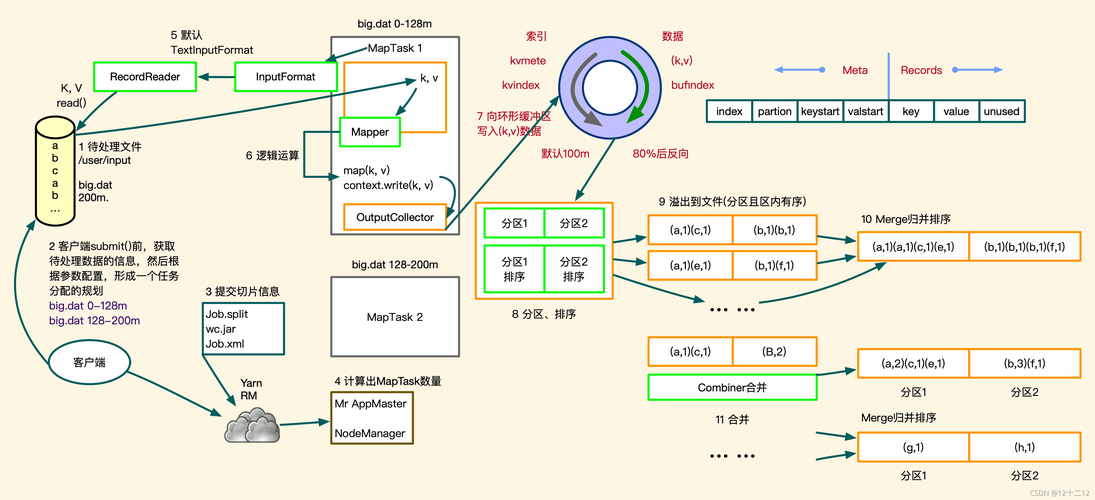
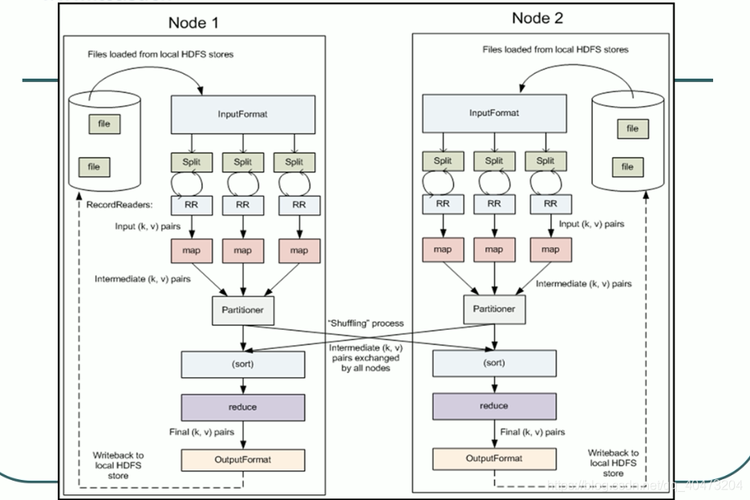
在 Map 阶段,我们将输入文件分割成多个小块,每个小块由一个 Map 任务处理,每个 Map 任务将读取其分配的文本块,并为每个单词生成一个键值对(单词,1)。
Map 函数伪代码
def map(text_chunk):
for word in text_chunk:
emit(word, 1) Shuffle 阶段
在 Shuffle 阶段,Map 任务的输出将被排序并根据键进行分组,以便将具有相同键的值传递给同一个 Reduce 任务。
Shuffle 阶段操作
排序:根据键对输出键值对进行排序。
分组:将具有相同键的值分组在一起。
Reduce 阶段
在 Reduce 阶段,每个 Reduce 任务将接收一组具有相同键的值,并将它们合并为一个结果,对于每个键,Reduce 任务将计算该键对应的所有值的总和。
Reduce 函数伪代码
def reduce(word, values):
count = sum(values)
emit(word, count) 数据输出
Reduce 阶段的输出将包含每个单词及其出现次数,这些结果可以写入到输出文件中。
输出示例
"apple", 5
"banana", 3
"orange", 7
通过使用 MapReduce 模型,我们可以有效地处理和分析大规模数据集,Map 阶段将数据分割成小块并生成中间键值对,Shuffle 阶段对中间键值对进行排序和分组,Reduce 阶段将具有相同键的值合并为最终结果,将最终结果写入到输出文件中。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/875165.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复