


MapReduce是一种编程模型,用于处理和生成大数据集,它借鉴了函数式编程中的map和reduce操作,将任务分解为两个阶段:映射(Map)和归约(Reduce),这种设计思想允许系统在大量计算机节点上并行处理数据,从而高效地处理大规模数据集。
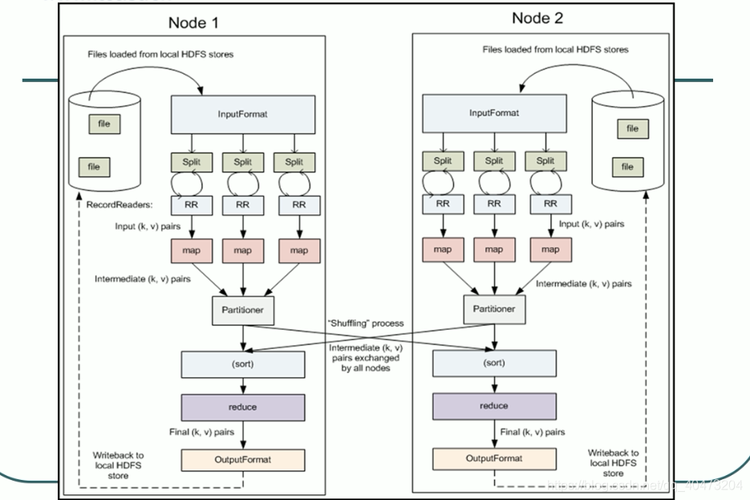

MapReduce设计思想
1. 数据分割(Input Split)
输入文件:原始数据通常存储在分布式文件系统中,如HDFS。
数据分割:输入文件被分割成多个数据块,每个数据块大小可以配置,通常是64MB或128MB。
2. 映射阶段(Map Phase)
Map任务分配:每个数据块分配给一个Map任务。
数据处理:Map任务读取数据块,按行解析,对每一行执行用户定义的Map函数。
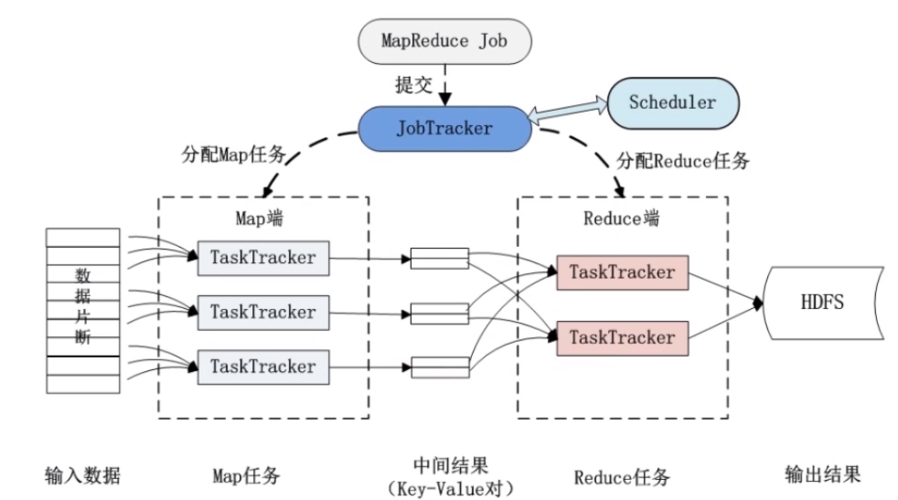
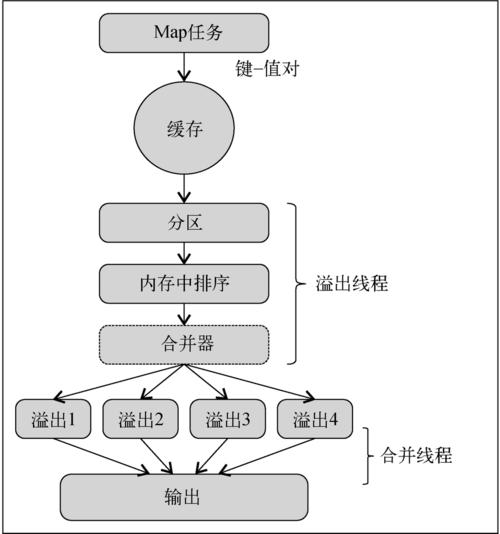
输出中间结果:Map函数输出键值对(keyvalue),这些键值对按照key进行排序和分组。
3. 洗牌阶段(Shuffle Phase)
数据传输:将Map任务输出的键值对传输到对应的Reduce任务。
排序和分组:在传输过程中,数据按key排序并分组,确保相同key的数据都发送到同一个Reduce任务。
4. 归约阶段(Reduce Phase)
数据处理:Reduce任务接收到所有具有相同key的键值对,然后执行用户定义的Reduce函数。
输出结果:Reduce函数输出最终结果,通常写入分布式文件系统。
5. 结果输出(Output)
合并结果:所有Reduce任务的结果最终合并为一个完整的输出文件。
MapReduce流程设计表格
| 阶段 | 子步骤 | 描述 | 示例 |
| 数据分割 | 输入文件分割 | 将大文件分割成小块以供Map任务处理 | 文件A被分割为块A1, A2, A3 |
| 映射阶段 | Map任务分配 | 每个数据块分配给一个Map任务 | 块A1分配给Map任务1 |
| 映射阶段 | 数据处理 | Map任务解析数据块,执行Map函数 | Map任务1处理块A1,输出中间键值对 |
| 洗牌阶段 | 数据传输 | 将Map输出传输到Reduce任务 | 键值对(K1,V1)传输到Reduce任务1 |
| 洗牌阶段 | 排序和分组 | 对传输的数据按key排序和分组 | (K1,V1),(K1,V2)被分组到一起 |
| 归约阶段 | 数据处理 | Reduce任务执行Reduce函数 | Reduce任务1处理(K1,V1),(K1,V2) |
| 归约阶段 | 输出结果 | Reduce任务输出最终结果 | Reduce任务1输出结果文件R1 |
| 结果输出 | 合并结果 | 所有Reduce结果合并为完整输出 | 文件R1, R2, R3合并为最终结果 |
MapReduce的设计思想简化了大规模数据处理的复杂性,通过将任务分解为可以在多个节点上并行执行的小任务,实现了高效的数据处理,这种模型适用于批处理类型的应用,特别是在数据挖掘、日志分析、机器学习等领域。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/874975.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复