


在数据库管理与操作中,确保数据的规范性和整洁性是一项重要的工作,特别是在处理大量数据时,往往会遇到重复数据的问题,这不仅浪费存储空间,还可能影响数据的统计与分析结果,尤其是在涉及多个字段的情况下,如何高效地进行去重,成为了一个值得探讨的问题,下面将详细介绍在MySQL中去重两个字段的方法及注意事项:
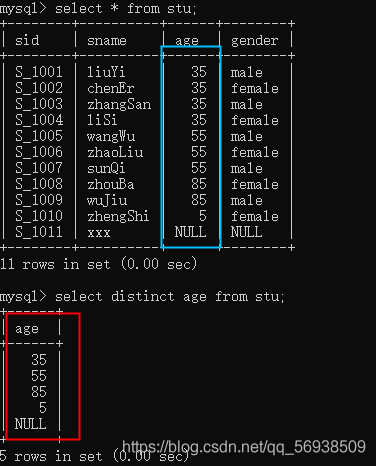

1、使用DISTINCT关键字进行去重
基本用法:当需要对数据表中的两个字段进行去重时,可以使用SELECT DISTINCT语句,在一个名为customers的表中,包含name和city两个字段,如需查询出所有不重复的姓名和城市组合,可使用如下SQL语句:
“`sql
SELECT DISTINCT name, city FROM customers;
“`
应用场景:此方法适用于快速获取不重复的字段组合,简单且直接。
2、通过GROUP BY进行去重
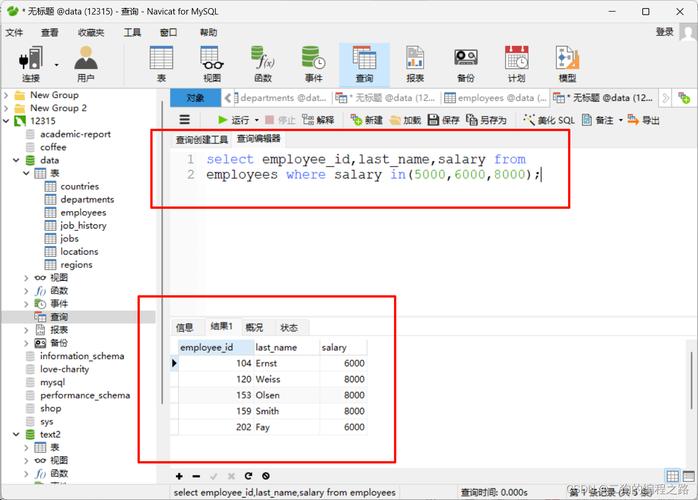
详细解析:GROUP BY语句常用于组合相同数据,并配合聚合函数如COUNT()使用,可以有效识别哪些数据是重复的,若需找出所有重复的name和city组合,可以使用如下语句:
“`sql
SELECT name, city, COUNT(*) as count FROM customers GROUP BY name, city HAVING count > 1;
“`
优势说明:此方法不仅能识别重复数据,还能显示每组重复数据的数量,有助于进一步分析。
3、利用INNER JOIN进行去重
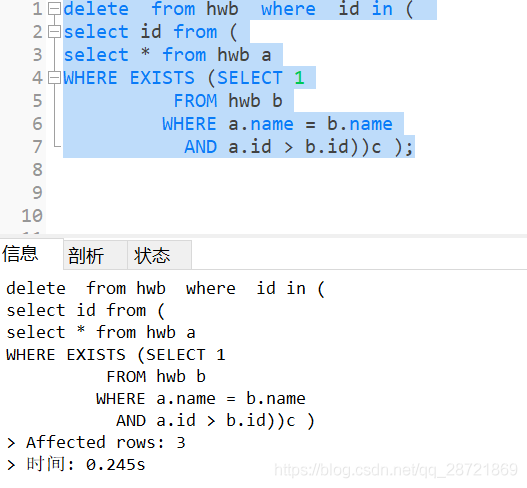
实操演示:当需要进行更复杂的去重操作时,比如基于其他条件同时去重,可以采用INNER JOIN,假设有一个orders表,需要基于客户ID和产品ID去重,可以使用如下查询:
“`sql
SELECT DISTINCT a.customer_id, b.product_id
FROM orders AS a
INNER JOIN (SELECT DISTINCT customer_id, product_id FROM orders) AS b
ON a.customer_id = b.customer_id AND a.product_id = b.product_id;
“`
场景适配:此方法适合在需要考虑多个相关表的数据关联时使用,能够有效地整合和去重。
4、ROW_NUMBER()窗口函数去重
高级应用:对于需要基于复杂排序或特定条件去重的场合,可以使用ROW_NUMBER(),针对每个姓名和城市的首次出现赋予序号:
“`sql
SELECT name, city
FROM (
SELECT name, city, ROW_NUMBER() OVER(PARTITION BY name, city ORDER BY id) as row_num
FROM customers
) t
WHERE t.row_num = 1;
“`
功能解释:此函数提供了强大的排序和分区能力,非常适合于复杂的数据去重需求。
5、数据备份与恢复
操作前准备:在进行任何去重操作之前,应该先备份原始数据,以防不慎丢失重要信息。
数据恢复策略:确保有明确的数据恢复流程,以便在操作失误时能迅速恢复数据。
可以看到每种方法都有其适用的场景和特点,在实际工作中,选择合适的去重策略非常重要,它能够帮助更好地管理和维护数据库的健康状态,操作前的准备工作也同样重要,不可忽视。
FAQs
Q1: 在实际操作中,如果误删了非重复的数据怎么办?
A1: 如果在去重操作中不慎删除了重要的非重复数据,应立即停止任何写入操作,并从最近的备份中恢复数据,建议在非生产环境中测试所有去重脚本,确保其正确性后再在生产数据库上运行。
Q2: 去重操作会影响数据库性能吗?
A2: 是的,去重操作可能会暂时增加数据库的负载,尤其是当处理大量数据时,建议在系统负载较低的时段执行这些操作,并监控数据库的性能指标,确保系统稳定。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/874798.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复