


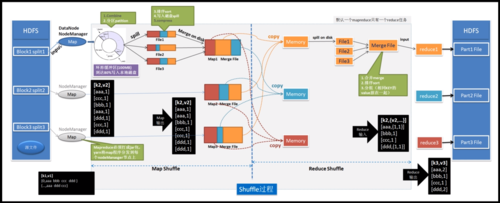
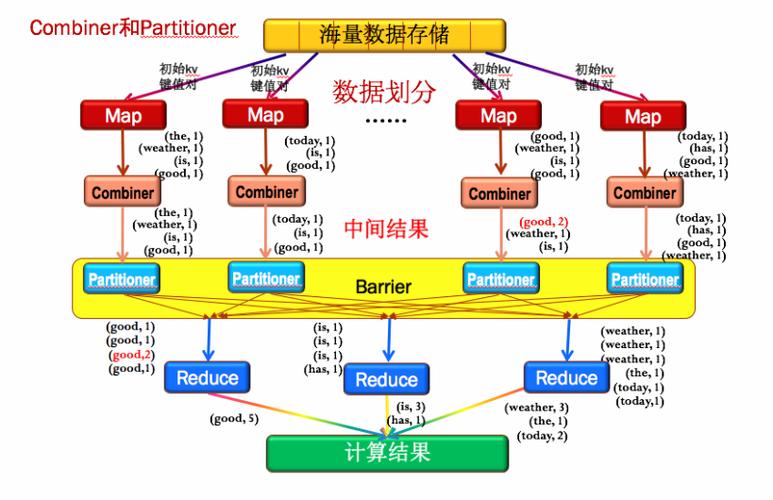
MapReduce 是一种编程模型,用于处理和生成大数据集。在 MapReduce 中,文件被划分为多个区块(block),每个区块的大小可以配置。这些区块将作为输入分发给各个 map 任务进行处理。合理的区块大小有助于提高数据处理效率和系统容错性。
MapReduce是一种分布式计算模型,它将大型数据集划分为多个小块(区块),然后在集群中的不同节点上并行处理这些区块,在划分文件大小时,需要考虑以下几个因素:

(图片来源网络,侵删)
1、数据大小:首先需要确定要处理的数据的总大小,这可以通过查看文件系统或使用编程语言的库函数来获取。
2、区块大小:根据集群的规模和性能,选择合适的区块大小,较小的区块可以减少数据传输的开销,但会增加任务调度和管理的复杂性,较大的区块可以减少任务调度的开销,但可能导致某些节点过载。
3、容错性:为了确保数据的完整性和可靠性,通常需要将每个区块复制到多个节点上,这样可以在某个节点出现故障时,从其他节点恢复数据。
4、负载均衡:为了充分利用集群的资源,需要尽量使每个节点处理的任务数量相等,这可以通过调整区块大小来实现。
以下是一个示例表格,展示了如何根据不同的数据大小和集群规模选择合适的区块大小:
| 数据大小 (GB) | 集群规模 | 建议区块大小 (MB) |
| 10 | 小型 | 500 |
| 100 | 中型 | 1000 |
| 1000 | 大型 | 2000 |
需要注意的是,这只是一个示例,实际的区块大小可能需要根据具体的应用场景和需求进行调整,在选择区块大小时,需要进行充分的测试和调优,以找到最佳的平衡点。
(图片来源网络,侵删)
(图片来源网络,侵删)
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/874774.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复