


MapReduce是一种编程模型,用于处理和生成大数据集。它包含两个主要阶段:Map阶段将数据分成小块并进行处理,而Reduce阶段则将结果汇总。这种模式适用于并行计算,可以高效地处理海量数据。
MapReduce并行计算框架

(图片来源网络,侵删)
深入理解MapReduce模型与应用开发
1、MapReduce概念与设计哲学
分布式处理核心思想
Map与Reduce逻辑分离
强调计算向数据靠拢
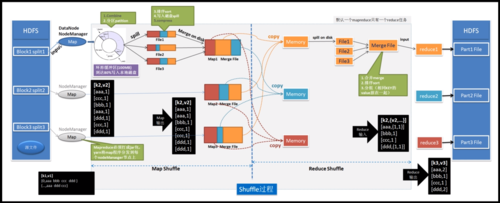
2、MapReduce体系结构
Master/Slave架构
(图片来源网络,侵删)
数据流与控制流分离
容错机制与任务监控
3、编程模型深度解析
Map函数编程范式
Reduce函数执行流程
Shuffle过程优化策略
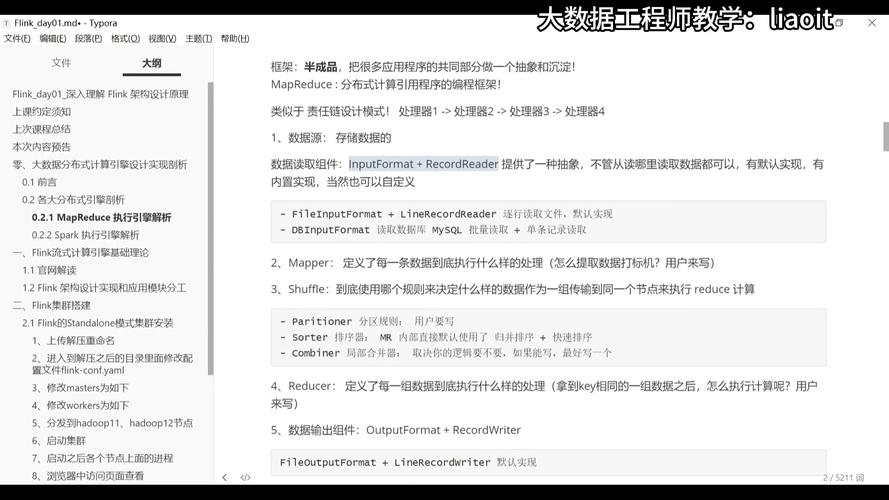
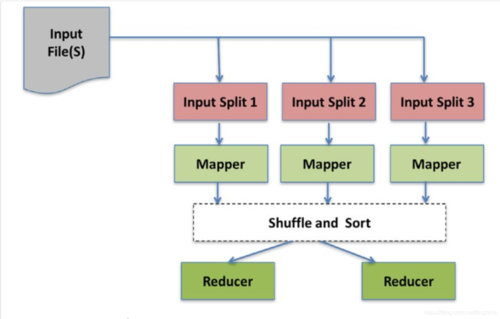
4、数据处理流程
(图片来源网络,侵删)
数据输入与分片机制
并行处理与结果汇总
输出格式与数据写入
5、MapReduce应用实例
日志分析案例
大数据集排序问题
机器学习数据处理
6、性能优化与调优策略
系统配置与参数调优
数据倾斜问题解决
高级API使用指南
7、版本演化与生态系统
Hadoop MapReduce版本变迁
与其他分布式系统比较
生态系统兼容性与扩展性
8、企业级部署实践
集群搭建与配置要点
安全性、稳定性考量
故障恢复与数据备份
9、未来趋势与挑战
云计算环境下的适应
实时处理与流计算整合
开源社区与技术迭代
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/874508.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复