


在大数据技术领域,MapReduce和Spark是两种被广泛使用的分布式计算框架,它们各自的特点和数据处理方式在处理大规模数据时发挥着重要作用,本文将对MapReduce和Spark的位置(shuffle过程)进行深入分析,并探讨两者的不同应用场景和技术特性。
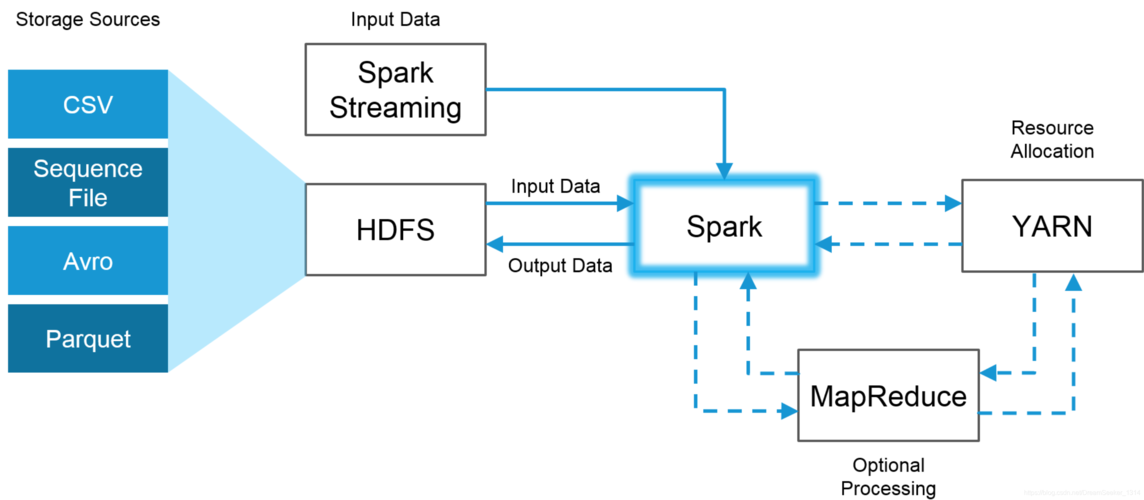

MapReduce的Shuffle过程
MapReduce模型主要由两个阶段组成:映射(Map)和规约(Reduce),在Map阶段,数据经过过滤和分类;而在Reduce阶段,则进行数据的计算和合并,Map和Reduce之间的数据传递是通过Shuffle过程实现的,它是连接这两个阶段的桥梁。
Shuffle过程可以细分为以下几个步骤:Map任务将输出的数据对不断地写入到一个内存中的环形缓冲区结构中,当缓冲区达到一定阈值时,就会触发溢写过程,将数据写入到磁盘,这些数据会被排序和合并,以便于Reduce任务能够高效地读取和处理这些数据,整个过程涉及多次的磁盘读写操作,这可能会成为性能瓶颈。
Spark的基于内存计算模型
不同于MapReduce的是,Spark提供了一种基于内存的计算模型,它可以将Job的中间输出结果保存在内存中,从而大大减少了对HDFS的读写需求,这一特性使得Spark在需要迭代计算的场景,如数据挖掘和机器学习,具有明显的优势。
Spark中的RDD(Resilient Distributed Dataset)是一个不可变的分布式对象集合,每个RDD都可以通过转换操作生成新的RDD,Spark拥有自己的shuffle过程,它同样负责数据的重分区,但与MapReduce不同的是,Spark试图通过在内存中处理数据来优化这一过程,这种方式在处理迭代算法时能显著减少时间开销。
MapReduce与Spark的对比
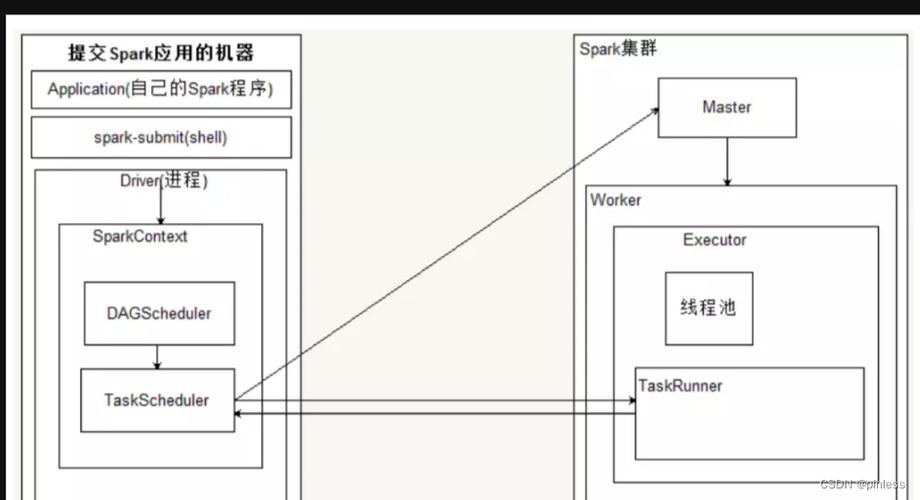
MapReduce更适合于批量和离线处理,它的设计初衷就是为了处理大量的非结构化数据,如网页爬行数据、日志文件等,而Spark则更加重视实效性,支持近实时处理,适用于需要快速迭代的数据挖掘与机器学习场景,在技术特性上,Spark相较于MapReduce提供了更高效的内存计算能力,以及更为灵活的数据转换与操作接口。
虽然Spark可以在许多场景下替代MapReduce,提供更高的效率,但MapReduce仍然在大数据处理领域占有一席之地,特别是在处理大规模非结构化数据时,选择哪种工具,通常取决于具体的使用场景和需求。
相关FAQs
Q1: Spark与MapReduce相比有哪些显著优势?
A1: Spark的主要优势在于其基于内存的计算能力,允许中间计算结果存储在内存中,从而大幅提高迭代算法的运算速度,Spark提供了更加灵活和强大的数据处理API,支持流数据处理和复杂查询操作,且易于编程和部署。
Q2: 在什么情况下应该选择使用MapReduce而不是Spark?
A2: 尽管Spark提供了许多优化和便利,但对于一些不需要频繁迭代的大批量数据处理任务,特别是那些可以接受较长处理延迟的场景,MapReduce可能仍是一个合适的选择,由于MapReduce已经存在多年,许多成熟的Hadoop生态系统工具和库都是围绕其设计的,对于已经在Hadoop生态系统中投入大量资源的组织来说,继续使用MapReduce可能会更划算。
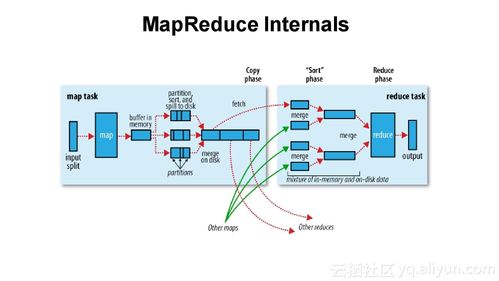
MapReduce和Spark各有千秋,在大数据框架的选择上,应根据实际业务需求和数据特点来决定使用哪种工具,理解它们的shuffle过程和数据处理机制,有助于更好地发挥各自的优势,实现数据价值的最大化。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/874254.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复