


MapReduce是面向海量数据处理的一种重要思想,也是一种用于对大规模数据进行分布式计算的编程模型,它允许开发者通过编写Map和Reduce两个函数来实现复杂的数据处理任务,下面将深入探索MapReduce的常用算法及其在应用开发中的一些关键概念。
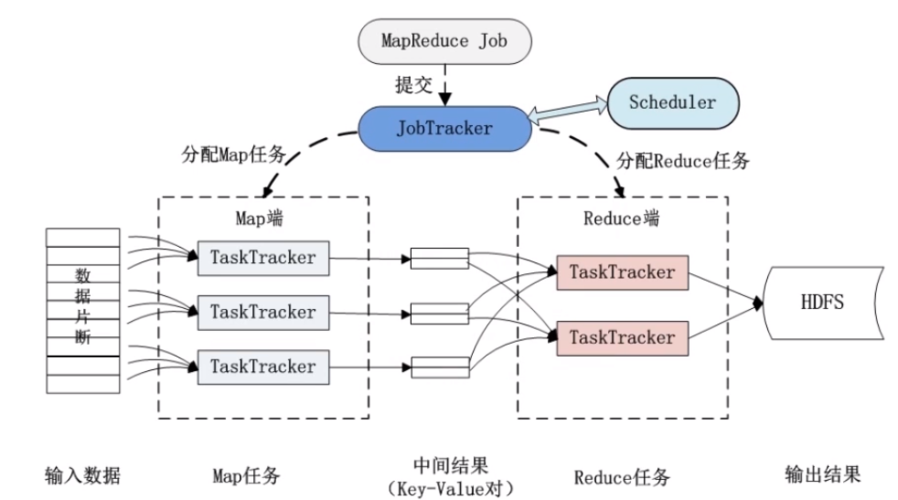

MapReduce常用算法
1、单词计数
经典的MapReduce案例,用于统计文本数据中各单词的出现频率。
Map阶段读取文本数据并输出单词及其计数(通常为1),Reduce阶段则对相同单词的计数进行累加。
2、数据去重
利用MapReduce的并行处理优势,对大数据集中的数据进行有意义的筛选,如计算不同种类的数据个数或从日志中解析独立访客数。
3、排序
对数据集按照某个Key进行升序或降序排列,常见于数据处理与分析中,如快速排序算法。
4、TopK
对源数据进行排序,提取前K个数据,这一算法常通过堆(Heap)来实现,广泛应用于需要选取最大或最小元素的任务中。
5、选择
从指定的关系中选择符合条件的元组组成新的关系,类似于关系型数据库中的选择操作。
MapReduce应用开发常用概念
1、编程模型
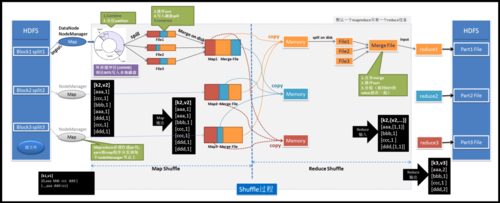
MapReduce核心功能是将用户编写的业务逻辑代码与自带组件整合,形成完整的分布式运算程序,运行在Hadoop集群上。
2、Map和Reduce阶段
用户需实现Map和Reduce两个函数,Map函数负责转换输入数据为键值对,而Reduce函数则处理这些键值对,输出最终结果。
3、Mapper与Reducer
Mapper是实现Map阶段的核心组件,负责接收输入数据并转换为键值对;Reducer则处理这些键值对,执行聚合操作等。
4、数据输入输出
MapReduce框架根据InputFormat切割数据集并提供给Map任务处理,而OutputFormat则负责将生成的键值对以特定格式输出。
MapReduce作为一个强大的分布式计算框架,其常用的算法及应用开发中的关键概念对于处理大规模数据集至关重要,掌握了这些基础知识后,开发者可以更加有效地利用MapReduce来处理复杂的数据问题,进而在大数据领域发挥重要作用。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/873823.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复