


MapReduce是一种编程模型,用于处理和生成大数据集的并行算法,它由两个主要步骤组成:Map(映射)和Reduce(归约)。
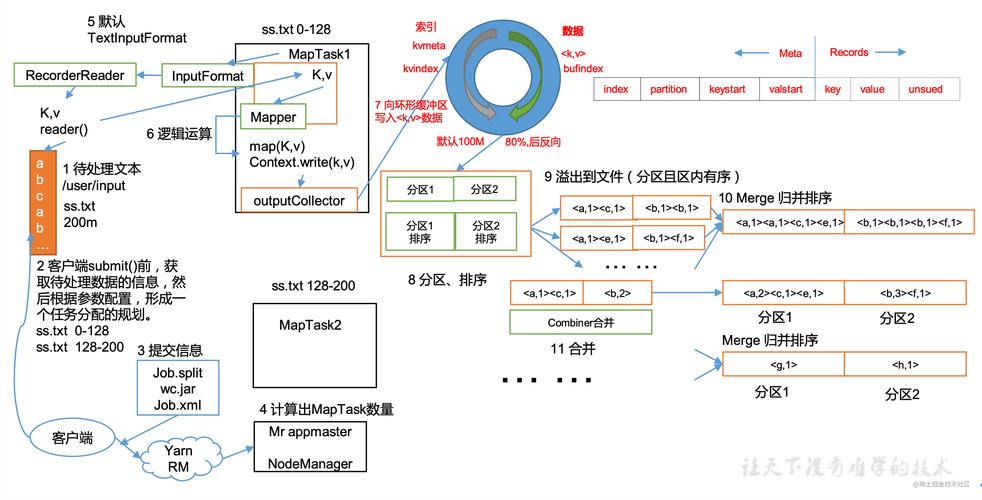

1. Map阶段
在Map阶段,输入数据被分割成多个独立的块,然后每个块被一个Map函数处理,Map函数接收输入数据并产生中间键值对,这些键值对随后被排序并分组,以便相同的键可以一起传递给Reduce函数。
示例代码(Python):
def map_function(input_data):
# 假设输入数据是一个包含单词的列表
for word in input_data:
# 输出键值对,键是单词,值是1
yield (word, 1) 2. Reduce阶段
在Reduce阶段,所有具有相同键的键值对被收集在一起,并由Reduce函数处理,Reduce函数接收一组键值对,并对它们进行处理以生成最终结果,Reduce函数会将键值对的值合并成一个单一的输出值。
示例代码(Python):
from collections import defaultdict
def reduce_function(key, values):
# 计算每个单词的出现次数
count = sum(values)
return count 3. MapReduce程序设计流程
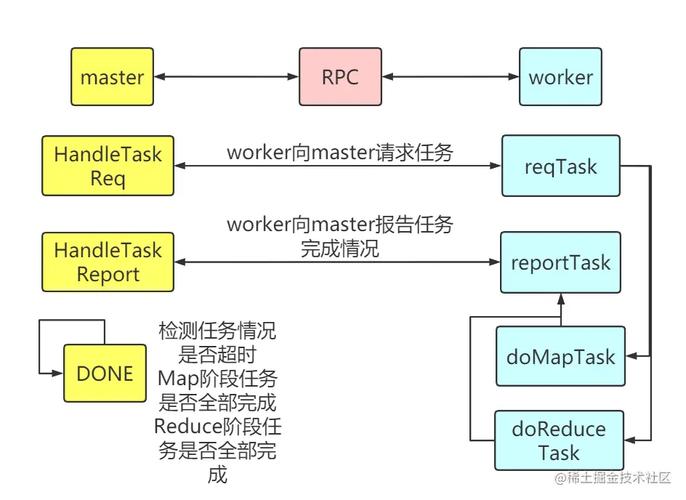
以下是一个简单的MapReduce程序设计的流程:
1、定义Mapper:编写一个函数,该函数接受输入数据并生成中间键值对。
2、定义Reducer:编写一个函数,该函数接受中间键值对并生成最终结果。
3、配置MapReduce作业:设置输入数据、输出路径、Map和Reduce函数等参数。
4、运行MapReduce作业:提交作业到集群或本地环境执行。
5、获取结果:从输出路径中读取最终结果。
4. MapReduce框架

有许多开源的MapReduce框架可用于实现MapReduce程序,例如Hadoop、Apache Spark等,这些框架提供了分布式计算的能力,可以在多台机器上并行处理大量数据。
5. MapReduce的优势
可扩展性:MapReduce可以轻松地扩展到数千个节点,以处理大规模数据集。
容错性:如果某个节点发生故障,MapReduce框架会自动重新分配任务到其他节点。
灵活性:MapReduce可以处理各种类型的数据,包括结构化和非结构化数据。
6. MapReduce的缺点
性能限制:由于MapReduce需要大量的磁盘I/O操作,对于实时数据处理或低延迟应用可能不是最佳选择。
编程复杂性:编写MapReduce程序需要熟悉特定的框架API和编程模型。
资源利用率:在某些情况下,MapReduce可能无法充分利用所有可用的资源,导致性能瓶颈。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/873397.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复