


MapReduce队列及其配置

MapReduce是Hadoop生态系统中的一个核心组件,用于处理大规模数据集,其基本操作包括映射(Map)和归约(Reduce)两个阶段,分别由Mapper和Reducer执行,在多用户环境下,为了优化资源分配和作业调度,通常会使用不同的调度器来管理作业队列,将详细解析MapReduce中队列的配置和管理方法。
MapReduce 的执行过程与队列的角色
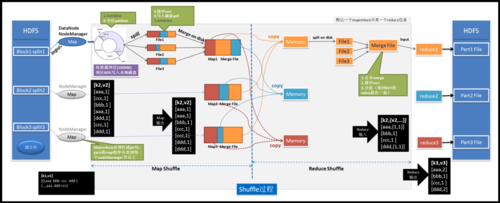
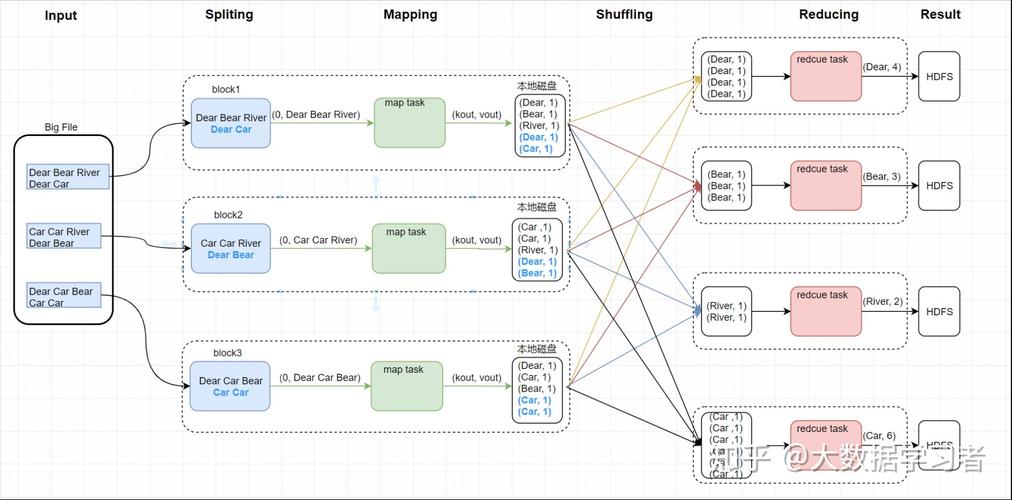
1、MapReduce 的基本流程
MapReduce 通过Mapper任务读取HDFS中的数据文件,处理后输出;Reducer任务则接收Mapper的输出作为输入数据,处理完输出到HDFS文件中。
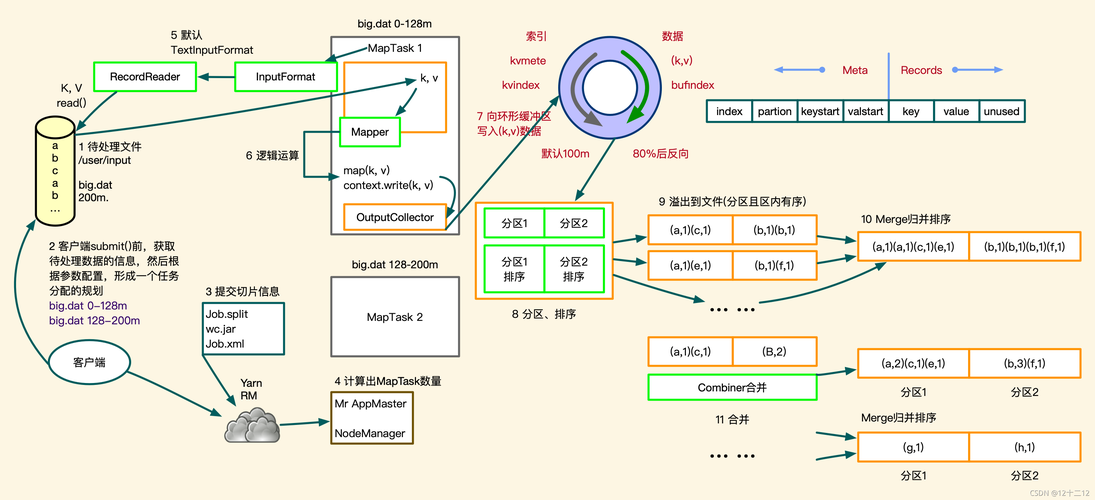
2、Mapper 任务的执行详解
每个Mapper任务是一个Java进程,它将HDFS中的文件解析成多个键值对,经过覆盖的map方法处理后再输出。
Mapper任务的处理可以分为六个阶段,首先是文件的分片(InputSplit),每个分片大小固定。
3、队列在 MapReduce 中的作用
队列主要用于管理不同类型和优先级的作业,合理分配计算资源。
理论上可以存在多个队列,每个队列可设定不同的资源分配比例和计算能力。
创建与配置队列
1、指定队列提交任务
在MapReduce中,可以通过设置参数mapreduce.job.queuename来指定提交的队列名称。
执行任务时可设定参数使任务提交到online或offline队列。
2、队列命令的使用
老版本的Hadoop使用set mapred.job.queue.name=queue3命令,新版本则使用SET mapreduce.job.queuename=queue3。
这些命令允许用户在运行MR作业时明确指定使用的队列。
3、多队列资源分配
可以在Hadoop中创建多个队列,如default、online、offline,并分配不同的资源比例,比如70%、10%、20%。
调度器的选择与配置
1、容量调度器(Capacity Scheduler)
容量调度器允许创建多个队列,并为每个队列设置特定的容量保证。
它适用于共享集群的场景,能保证每个队列都有固定的资源最小配额。
2、公平调度器(Fair Scheduler)
公平调度器也是常用的调度器之一,它尝试为所有作业公平地共享资源,等量分配。
可以通过配置文按需设置每个队列的资源分配策略。
设置优先级与调度策略
1、作业优先级
可以为每个提交到Hadoop的作业设置优先级,例如LOW、VERY_LOW、NORMAL(默认)、HIGH、VERY_HIGH等。
优先级高的任务在资源分配时会获得一定的优势。
2、调度策略的配置
管理员可以在容量调度器或公平调度器中设置具体的调度策略,如基于内存或执行时间的限制。
这影响任务的执行顺序和资源获取频率。
通过上述分析,我们了解了MapReduce中队列的配置和管理方式,以及如何通过不同调度器来实现资源的高效利用,在实际操作过程中,根据具体需求选择适合的调度策略和队列配置是关键。
相关问答FAQs
Q1: 如何在Hadoop中设置作业的优先级?
A1: 可以通过设置参数mapreduce.job.priority来调整作业的优先级,可选的值有LOW、VERY_LOW、NORMAL(默认)、HIGH、VERY_HIGH,若需设置作业为高优先级,可在作业提交时添加参数D mapreduce.job.priority=HIGH。
Q2: 在新版Hadoop中应如何使用命令指定任务队列?
A2: 在新版Hadoop中,应使用命令SET mapreduce.job.queuename=队列名;来指定任务队列,若你的作业需要提交到名为“critical”的队列,相应的命令会是SET mapreduce.job.queuename=critical;。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/872852.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复