


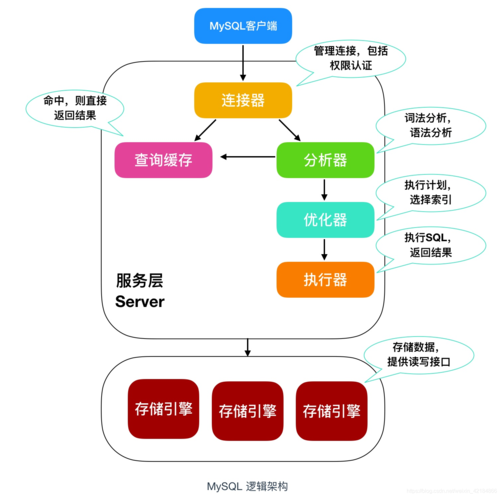
INNER JOIN或WHERE子句结合IN操作符来实现。若要获取表A和表B中ID相同的记录的交集,可以使用SELECT * FROM A INNER JOIN B ON A.ID = B.ID;或者SELECT * FROM A WHERE A.ID IN (SELECT B.ID FROM B);。在数据库管理与操作中,交集操作是一种基础而重要的功能,MySQL 是一个广泛应用在全球的开源关系型数据库管理系统,它提供了强大的数据处理能力,包括交集、并集、差集等集合运算,下面将详细探讨如何在 MySQL 数据库中实现交集操作:

创建测试数据表
为了进行交集操作,首先需要有至少两个具有相似结构的数据表,以下是创建示例数据表的 SQL 语句:
CREATE TABLE a_student (
id INT,
name VARCHAR(255)
);
CREATE TABLE b_student (
id INT,
name VARCHAR(255)
); 插入测试数据
向这两个表中插入一些测试数据:
INSERT INTO a_student (id, name) VALUES (1, '张三'), (2, '李四'), (3, '王五'); INSERT INTO b_student (id, name) VALUES (2, '李四'), (3, '王五'), (4, '赵六');
使用 INTERSECT 获取交集
在标准 SQL 中,INTERSECT 用来获取两个查询结果的交集,但在 MySQL 中,由于直到版本 8.0 才引入了INTERSECT,可以使用如下方式来模拟:
使用INNER JOIN 或IN 子句:

如果只是简单的想找到两个表中相同的记录,可以使用INNER JOIN:
SELECT a.id, a.name FROM a_student AS a INNER JOIN b_student AS b ON a.id = b.id AND a.name = b.name;
或者使用IN 子句:
SELECT id, name FROM a_student WHERE (id, name) IN (SELECT id, name FROM b_student);
使用UNION ALL 和GROUP BY 结合HAVING:
对于更复杂的交集查询,可以首先合并两个集合,然后通过分组和计数来找出交集部分:
SELECT id, name
FROM (
SELECT id, name FROM a_student
UNION ALL
SELECT id, name FROM b_student
) AS combined
GROUP BY id, name
HAVING COUNT(*) > 1; 性能优化建议
当处理大量数据时,交集操作可能会遇到性能瓶颈,以下是一些优化建议:
使用索引: 确保涉及到交集操作的列上有适当的索引,这可以显著提高查询速度。
分析执行计划: 使用EXPLAIN 命令来分析查询的执行计划,找出可能的性能瓶颈。
适当使用缓存: 利用数据库的缓存机制可以减少重复查询的开销。
虽然 MySQL 在早期版本中不支持直接使用INTERSECT,但通过以上方法依然可以有效地实现交集操作,合理设计和优化查询语句对于提高数据库性能至关重要,希望这些信息对您有所帮助,并能在您的数据库操作中发挥作用。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/872816.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复